Last year, I had a lot of fun working with a fantastic little tool that a colleague of mine created, to analyse and enhance Spotify playlists using Neo4j. While I was working on that blogpost, and I was experimenting with what little I know of Python code, I came across another example project that Spotify actually highlighted on their website: it's called Six Degrees of Kanye West and it's simply amazing.
The idea behind this site seems to be similar to the "Six Degrees of Kevin Bacon": if you have ever worked with Kevin directly, your Bacon Number is 1. If you have worked with someone that has worked with Kevin, then your Bacon Number is 2. Etc etc - and then this is applied to the idea of musicians working together on songs.
For example, if you go there and you look up some unknown artist (like then inimitable Belgian schlager singer, Helmut Lotti), like this:
You then get a really interesting result:
Meaning that our dear friend Helmut is only 4 "hops" removed from the big Kanye. Helmut's Kanye Number is therefore: 4.
So, what I am going to try to do in this blogpost series, is to replicate that Using the Musicbrainz dataset. MusicBrainz is an open music encyclopedia that collects music metadata and makes it available to the public. You can access it freely on their website, but you can also just download a copy of the data and take it for a spin. Guess what I am going to do?
Musicbrainz uses a relational infrastructure to do what it's doing - specifically Postgres. After a few failed attempts using the dump of the RDBMS, I finally ended up installing it on my laptop using from this process - which uses Docker. Here's how this worked.
First, I had to download the Github repository and change current working directory with:
git clone https://github.com/metabrainz/musicbrainz-docker.git
cd musicbrainz-docker
Then I could build the required Docker images with a simple command
sudo docker-compose build
and continue with the creation of the local Postgres database in the Docker container.
sudo docker-compose run --rm musicbrainz createdb.sh -fetch
Once this was finished, I have a full Docker setup running - without too much trouble:
Once I had this, I needed to publish ports of all services to the rest of my environment - but in order to do that I first had to go through through the small step of upgrading bash on OSX. Not too problematic - and then I could just run this command:
admin/configure add publishing-all-ports
and proceed with starting the system.
sudo docker-compose up -d
There we go - we have a local Musicbrainz database, which I can explore in DBeaver just to check if everything is working.
Sure enough - all is good! So now we can get towork with the MusicBrainz schema, which you can find over here. Here's what (part of) the model looks like:
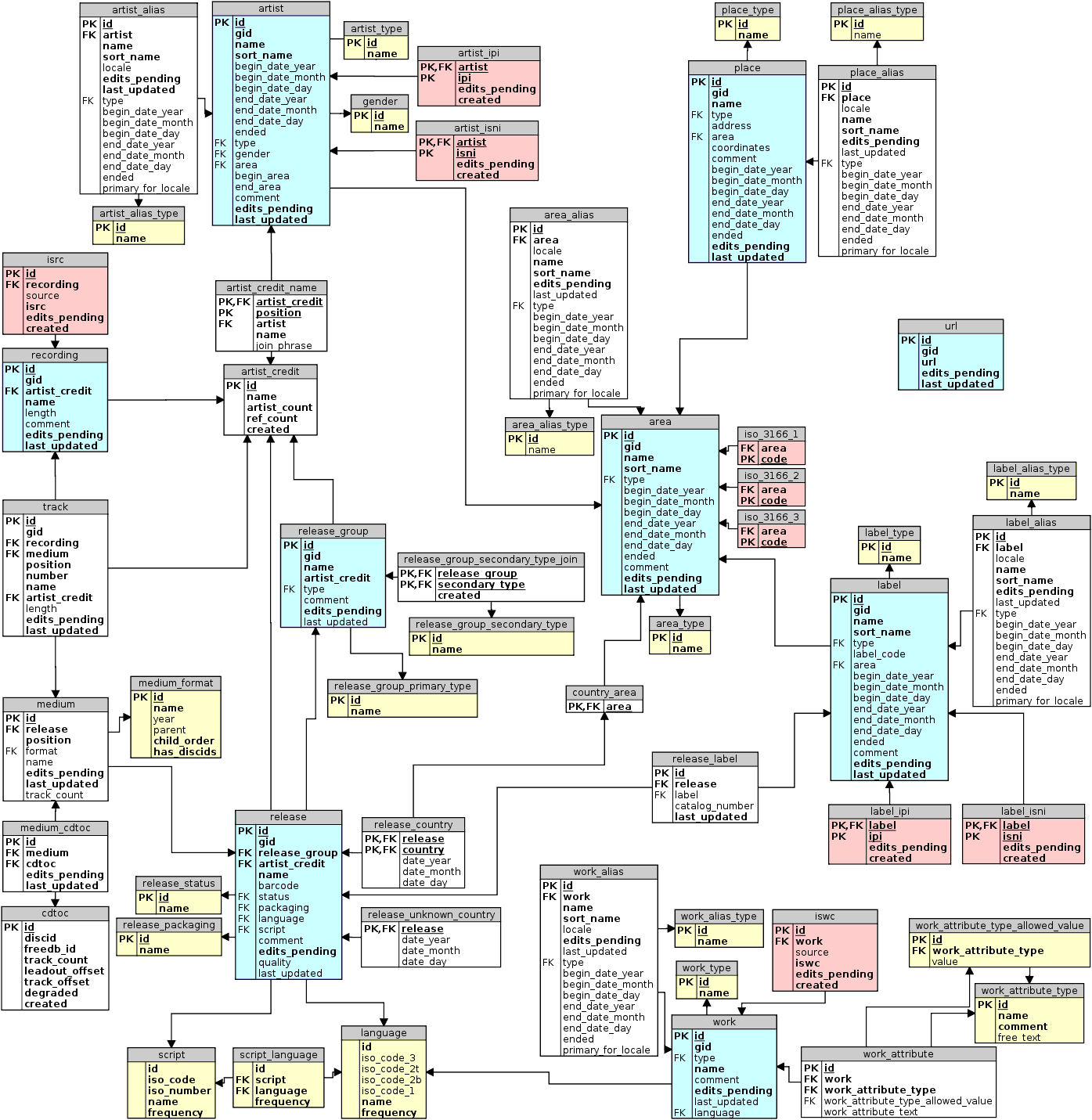
In the next episode, we will go and start the import process of the MusicBrainz database into our beloved graph database, Neo4j.
CU then,
Rik Van Bruggen