Javaのデフォルトの文字コードは決まっていない。実行時の環境により都度かわる。それが結論。
以下のようなコードをWindows7/10のEclipse(Pleiades 2018.12)で実行した場合、
String[] names = {
"java.version",
"java.vm.version",
"java.vendor.url",
"file.encoding",
"sun.jnu.encoding"
};
for (String name : names) {
System.out.println(name + "=" + System.getProperty(name));
}
System.out.println("default encoding=" + Charset.defaultCharset().name());結果は、
java.version=1.8.0_202
java.vm.version=25.202-b08
java.vendor.url=https://adoptopenjdk.net/
file.encoding=UTF-8
sun.jnu.encoding=MS932
default encoding=UTF-8
こんな感じになる。
他のJava実行環境で試しても
- Oracle JDK6
- Oracle JDK8
- AdoptOpenJDK 8
- AdoptOpenJDK 11
- Zulu8
いずれも、同じ文字コードを返す。
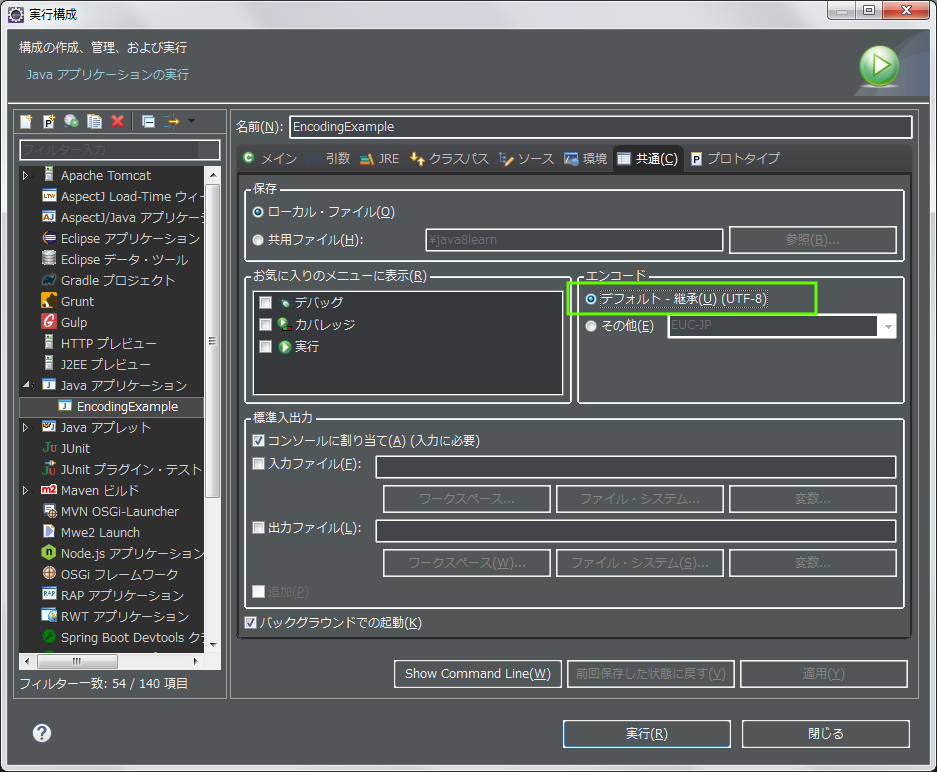
これはEclipse実行時に指定されているのであった。
UTF-8になっているのは、これはEclipseの実行構成で指定されている文字コードである。
なのでEclipseの実行構成の設定をかえると、デフォルトの文字コードもかわる。
以下のコードを追加して、JavaVMに渡されているVM引数も表示してみる。
RuntimeMXBean runtimeMxBean = ManagementFactory.getRuntimeMXBean();
for (String vmArg : runtimeMxBean.getInputArguments()) {
System.out.println(vmArg);
}結果は、
-Dfile.encoding=UTF-8
java.version=1.8.0_202
java.vm.version=25.202-b08
java.vendor.url=https://adoptopenjdk.net/
file.encoding=UTF-8
sun.jnu.encoding=MS932
default encoding=UTF-8
Eclipseが実行時に -Dfile.encoding=UTF-8 を付与していることが分かる。
上記プログラムをコンソールから実行してみる。
set JAVA_HOME=C:\java\pleiades201812\java\8
mvnw clean package
%JAVA_HOME%\bin\java -jar target\java8learn.jarMaven Wrapperでビルドして、実行可能jarを生成し、これを実行する。
すると、以下のような結果が得られる。
java.version=1.8.0_192
java.vm.version=25.192-b12
java.vendor.url=http://java.oracle.com/
file.encoding=MS932
sun.jnu.encoding=MS932
default encoding=windows-31j
VM引数は指定されていない。
windows-31jと表示されているが、これはMS932と同じものである。単なるAliasである。
これは、他のJava実行環境で試すと
- Oracle JDK6
- Oracle JDK8
- AdoptOpenJDK 8
- AdoptOpenJDK 11
- Zulu8
いずれも、同じ文字コードが得られた。
JAVAの文字コード設定は2つある。
- file.encodingシステムプロパティ
- sun.jnu.encodingシステムプロパティ1
このうち、file.encodingシステムプロパティが、デフォルトのCharsetとして使われている。
/**
* Returns the default charset of this Java virtual machine.
*
* <p> The default charset is determined during virtual-machine startup and
* typically depends upon the locale and charset of the underlying
* operating system.
*
* @return A charset object for the default charset
*
* @since 1.5
*/
public static Charset defaultCharset() {
if (defaultCharset == null) {
synchronized (Charset.class) {
String csn = AccessController.doPrivileged(
new GetPropertyAction("file.encoding"));
Charset cs = lookup(csn);
if (cs != null)
defaultCharset = cs;
else
defaultCharset = forName("UTF-8");
}
}
return defaultCharset;
}JVM起動時にSystemクラスの内部メソッドinitPropertiesが呼び出されてプロパティが設定されるが、 このinitPropertiesメソッドはNativeメソッドである。
これは、OpenJDK8のソースコードでは、以下のあたりに書かれている。
- http://hg.openjdk.java.net/jdk8/jdk8/jdk/file/687fd7c7986d/src/share/native/java/lang/System.c#l169
- http://hg.openjdk.java.net/jdk8/jdk8/jdk/file/687fd7c7986d/src/windows/native/java/lang/java_props_md.c#l314
このソースを読むと
GetJavaPropertiesという関数で環境変数等々から、さまざまな情報を取得して、それをプロパティに設定していることがわかる。
文字コードまわりとしては、GetJavaProperties関数内から、Windowsの場合ではWin32 APIを使って 2
/*
* query the system for the current system default locale
* (which is a Windows LCID value),
*/
LCID userDefaultLCID = GetUserDefaultLCID();
LCID systemDefaultLCID = GetSystemDefaultLCID();
LCID userDefaultUILang = GetUserDefaultUILanguage();といったコードで各種ロケールなどの情報を取得している。
このうち、GetUserDefaultLCID() が file.encoding の元ネタになるようである。
関連するコードを少し抜き出して、日本語のWindows環境下で実行してみると
int main()
{
LCID userDefaultLCID = GetUserDefaultLCID();
wchar_t * ret = (wchar_t*) malloc(16 * 2);
int codepage;
if (GetLocaleInfo(userDefaultLCID,
LOCALE_IDEFAULTANSICODEPAGE,
ret + 2, 14) == 0) {
codepage = 1252;
}
else {
codepage = _wtoi(ret + 2);
}
printf("codepage=%d", codepage);
}を実行すると、
codepage=932
という結果が返ってくる。
このGetUserDefaultLCIDで返されるコードページ932であれば「MS932」という文字列を作成し、これが file.encodingシステムプロパティに設定される。
実行時の環境によってfile.encodingシステムプロパティは変わる。
明示的にfile.encodingシステムプロパティを指定した場合は、そちらが優先される。
なので、(たとえ同一バージョンのJAVAであっても)デフォルトの文字コードが特定の何かであるかを期待することはできない。
以上、メモ終了。

{kind=link}