GRU (Gated Recurrent Unit) aims to solve the vanishing gradient problem (The problem is that in some cases, the gradient will be small, effectively preventing the weight from changing its value then the network stop learning) which comes with a standard recurrent neural network.
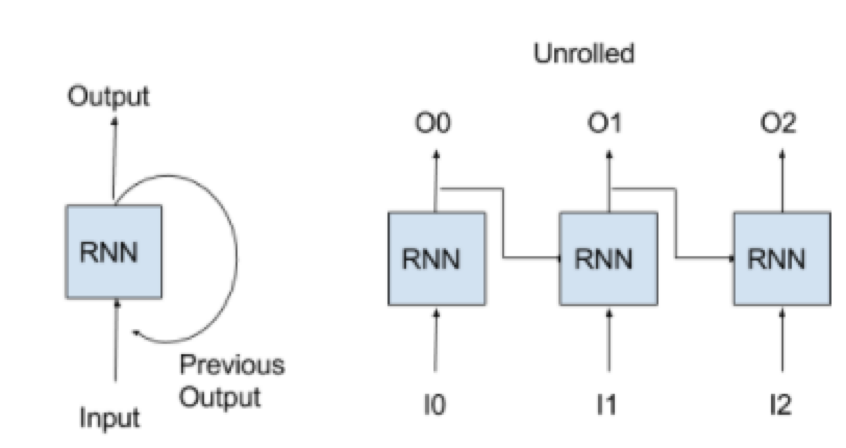
RNN network can predict output base on previous output or predict output by taking external input + previous output. It kind of ilterate process by taking previous output to generate new output in terms of processing sequence data.
As above diagram mentioned, there are external input (I0, I1, I2) and sequence output (O0, O1, O2)