GRU (Gated Recurrent Unit) aims to solve the vanishing gradient problem (The problem is that in some cases, the gradient will be small, effectively preventing the weight from changing its value then the network stop learning) which comes with a standard recurrent neural network.
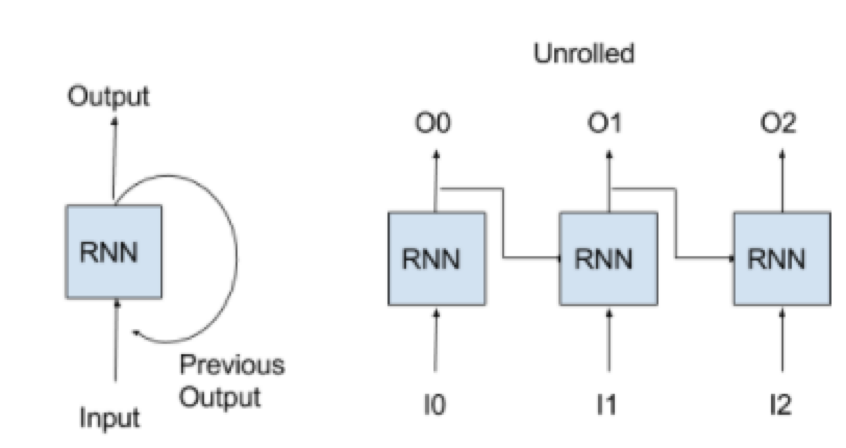
RNN network can predict output base on previous output or predict output by taking external input + previous output. It kind of ilterate process by taking previous output to generate new output in terms of processing sequence data.
As above diagram mentioned, there are external input (I0, I1, I2) and sequence output (O0, O1, O2)
I0 -> RNN produce output O0, (O0 + I1) -> RNN produce output O1, (O1 + I2) -> RNN produce output O2

The GRU is the newer generation of Recurrent Neural networks and is pretty similar to an LSTM. It only has two gates, a reset gate and update gate.
Gates are just neural network that regulate the flow information being passed from one step to next.
The update gate acts similar to the forget and input gate of an LSTM
The update gate helps the model to determine how much of the past information (from previous time steps) needs to be passed along to the future.
That is really powerful because the model can decide to copy all the information from the past and eliminate the risk of vanishing gradient problem.
Essentially, this gate is used from the model to decide how much of the past information to forget.
Now, you can see how GRUs are able to store and filter information using their update and reset gates. It keeps the relevant information and passes it down to the next time steps of the network. GRU network offering us a powerful tool to handle sequence data.