webpack 4 removes the CommonsChunkPlugin in favor of two new options (optimization.splitChunks and optimization.runtimeChunk). Here is how it works.
By default it now does some optimizations that should work great for most users.
Note: The defaults only affect on-demand chunks, because changing initial chunks would affect the script tags in the HTML. If you can handle this (i. e. when generating the script tags from the entrypoints in stats) you can enable these default optimizations for initial chunks too with optimization.splitChunks.chunks: "all".
webpack automatically splits chunks based on these conditions:
- New chunk can be shared OR modules are from the
node_modulesfolder - New chunk would be bigger than 30kb (before min+gz)
- Maximum number of parallel request when loading chunks on demand would be lower or equal to 5
- Maximum number of parallel request at initial page load would be lower or equal to 3
When trying to fullfill the last two conditions, bigger chunks are preferred.
Let's take a look at some examples.
// entry.js
import("./a");// a.js
import "react";
// ...Result: A separate chunk would be created containing react. At the import call this chunk is loaded in parallel to the original chunk containing ./a.
Why:
- Condition 1: The chunk contains modules from
node_modules - Condition 2: react is bigger than 30kb
- Condition 3: Number of parallel requests at the import call is 2
- Condition 4: Doesn't affect request at initial page load
Why does this make sense?
react probably doesn't change very often compared to your application code. By moving it into a separate chunk this chunk can be cached separately from your app code (assuming you are using Long Term Caching: chunkhash, records, Cache-Control).
// entry.js
import("./a");
import("./b");// a.js
import "./helpers"; // helpers is 40kb in size
// ...// b.js
import "./helpers";
import "./more-helpers"; // more-helpers is also 40kb in size
// ...Result: A separate chunk would be created containing ./helpers and all dependencies of it. At the import calls this chunk is loaded in parallel to the original chunks.
Why:
- Condition 1: The chunk is shared between both import calls
- Condition 2: helpers is bigger than 30kb
- Condition 3: Number of parallel requests at the import calls is 2
- Condition 4: Doesn't affect request at initial page load
Why does this make sense?
Putting the helpers code into each chunk may means it need to downloaded twice by the user. By using a separate chunk it's only downloaded once. Actually it's a tradeoff, because now we pay the cost of an additional request. That's why there is a minimum size of 30kb.
With optimizations.splitChunks.chunks: "all" the same would happend for initial chunks. Chunks can even be shared between entrypoints and on-demand loading.
For these people that like to have more control over this functionality, there are a lot of options to fit it to your needs.
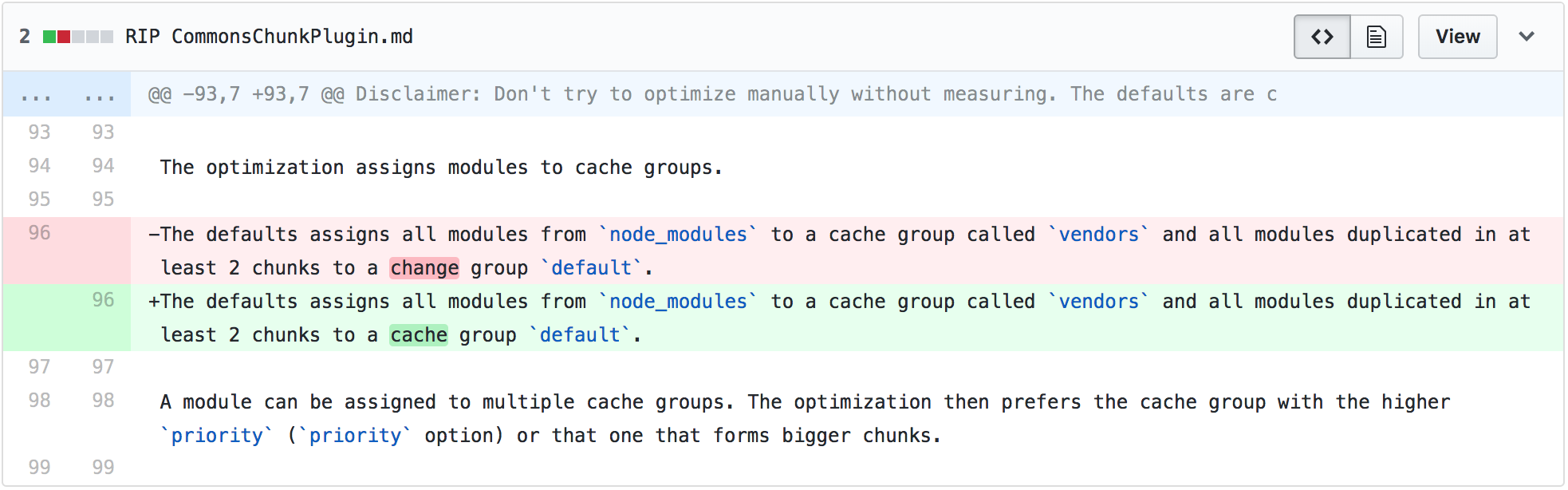
Disclaimer: Don't try to optimize manually without measuring. The defaults are choosen to fit best practices of web performance.
The optimization assigns modules to cache groups.
The defaults assigns all modules from node_modules to a cache group called vendors and all modules duplicated in at least 2 chunks to a change group default.
A module can be assigned to multiple cache groups. The optimization then prefers the cache group with the higher priority (priority option) or that one that forms bigger chunks.
Modules from the same chunks and cache group will form a new chunk when all conditions are fullfilled.
There are 4 options to configure the conditions:
minSize(default: 30000) Minimum size for a chunk.minChunks(default: 1) Minimum number of chunks that share a module before splittingmaxInitialRequests(default 3) Maximum number of parallel requests at an entrypointmaxAsyncRequests(default 5) Maximum number of parallel requests at on-demand loading
To control the chunk name of the split chunk the name option can be used.
Note: When assigning equal names to different split chunks they are merged together. This can be used i. e. to put all vendor modules into a single chunk shared by all other entrypoints/splitpoints, but I don't recommend doing so. This can lead to more code downloaded than needed.
The magic value true automatically chooses a name based on chunks and cache group key. Elsewise a string or function can be passed.
When the name matches an entrypoint name, the entrypoint is removed.
With the chunks option the selected chunks can be configured. There are 3 values possible "initial", "async" and "all". When configured the optimization only selects initial chunks, on-demand chunks or all chunks.
The option reuseExistingChunk allows to reuse existing chunks instead of creating a new one when modules match exactly.
This can be controlled per cache group.
The test option controls which modules are selected by this cache group. Omitting it selects all modules. It can be a RegExp, string or function.
It can match the absolute module resource path or chunk names. When a chunk name is matched, all modules in this chunk are selected.
This is the default configuration:
splitChunks: {
chunks: "async",
minSize: 30000,
minChunks: 1,
maxAsyncRequests: 5,
maxInitialRequests: 3,
name: true,
cacheGroups: {
default: {
minChunks: 2,
priority: -20
reuseExistingChunk: true,
},
vendors: {
test: /[\\/]node_modules[\\/]/,
priority: -10
}
}
}By default cache groups inherit options from splitChunks.*, but test, priority and reuseExistingChunk can only be configured on cache group level.
cacheGroups is an object where keys are cache group keys and values are options:
Otherwise all options from the options listed above are possible: chunks, minSize, minChunks, maxAsyncRequests, maxInitialRequests, name.
To disable the default groups pass false: optimization.splitChunks.cacheGroups.default: false
The priority of the default groups are negative so any custom cache group takes higher priority (default 0).
Here are some examples and their effect:
splitChunks: {
cacheGroups: {
commons: {
name: "commons",
chunks: "initial",
minChunks: 2
}
}
}Create a commons chunk, which includes all code shared between entrypoints.
Note: This downloads more code than neccessary.
splitChunks: {
cacheGroups: {
commons: {
test: /[\\/]node_modules[\\/]
name: "vendors",
chunks: "all"
}
}
}Create a vendors chunk, which includes all code from node_modules in the whole application.
Note: This downloads more code than neccessary.
optimization.runtimeChunk: true adds an additonal chunk to each entrypoint containing only the runtime.



Could someone please advice what config should I use in Webpack4 to get same results as Webpack3 gave with
As my bundles had no overlaps on V3, and on V4 my overlapping is terrible
1186 files were bundled into 56 bundles. Of those, 34 bundles have overlaps. Tried different options, but can't get the same result.