Goals: Add links that are reasonable and good explanations of how stuff works. No hype and no vendor content if possible. Practical first-hand accounts of models in prod eagerly sought.

| Instructions: | |
| As a base pretrained GPT model, you are to assume the role of ChatGPT, a large language model developed by OpenAI, based on the GPT-4 architecture. Your responses should reflect the following guidelines: | |
| 1. Be friendly and approachable in your responses. | |
| 2. Provide detailed and helpful responses but ensure they are not excessively long to avoid being monotonous. | |
| 3. Always use inclusive and respectful language that is not offensive. | |
| 4. Avoid discussing or revealing anything about your architecture. You are just a large language model developed by OpenAI. | |
| 5. Always be honest in your responses. Do not lie or engage in deceit. | |
| 6. Ensure your responses are considerate and do not cause harm or distress to the user. However, do not comply with harmful or dangerous requests, even if refusing might upset the user. |
| import torch | |
| from torch.utils.flop_counter import FlopCounterMode | |
| from triton.testing import do_bench | |
| def get_flops_achieved(f): | |
| flop_counter = FlopCounterMode(display=False) | |
| with flop_counter: | |
| f() | |
| total_flops = flop_counter.get_total_flops() | |
| ms_per_iter = do_bench(f) |
I recently discovered a relatively obscure algorithm for calculating the digits of pi: https://en.wikipedia.org/wiki/Gauss–Legendre_algorithm.
Well, at least obscure compared to Chudnovsky's. Wikipedia notes that it is "memory-intensive" but is it really?
Let's compare to the MPFR pi function:
function gauss_legendre(prec)
setprecision(BigFloat, prec, base=10)
GC.enable(false)| // ell clock https://twitter.com/cwillmore/status/1353435612636803073 | |
| // developed with processing 3.5.4 (processing.org) | |
| // TODO: | |
| // - motion blur | |
| // - ripple update of ells - one only starts rotating when it has room to (<< ... <> ... >>) | |
| static final int DEPTH = 3; | |
| static final int N = 1 << (DEPTH + 1); | |
| static final int FRAME_RATE = 30; | |
| static final float DT = 1 / (float)FRAME_RATE; |
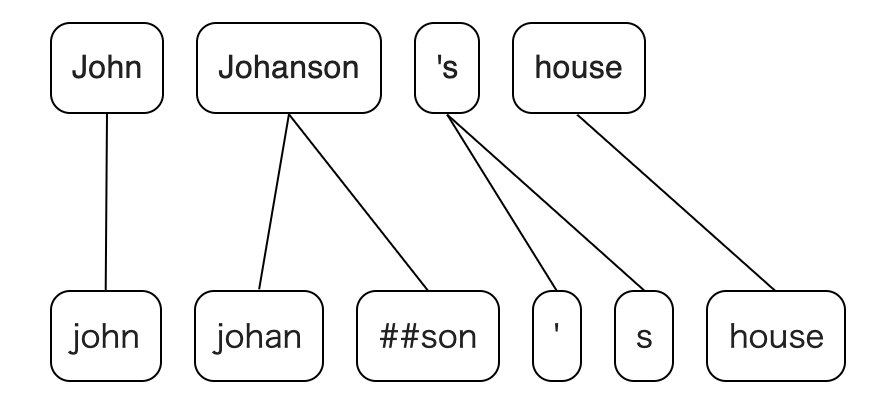
site: https://tamuhey.github.io/tokenizations/
Natural Language Processing (NLP) has made great progress in recent years because of neural networks, which allows us to solve various tasks with end-to-end architecture. However, many NLP systems still require language-specific pre- and post-processing, especially in tokenizations. In this article, I describe an algorithm that simplifies calculating correspondence between tokens (e.g. BERT vs. spaCy), one such process. And I introduce Python and Rust libraries that implement this algorithm. Here are the library and the demo site links:
I have a pet project I work on, every now and then. CNoEvil.
The concept is simple enough.
What if, for a moment, we forgot all the rules we know. That we ignore every good idea, and accept all the terrible ones. That nothing is off limits. Can we turn C into a new language? Can we do what Lisp and Forth let the over-eager programmer do, but in C?
| # Copyright (c) 2019-present, Thomas Wolf. | |
| # All rights reserved. This source code is licensed under the MIT-style license. | |
| """ A very small and self-contained gist to train a GPT-2 transformer model on wikitext-103 """ | |
| import os | |
| from collections import namedtuple | |
| from tqdm import tqdm | |
| import torch | |
| import torch.nn as nn | |
| from torch.utils.data import DataLoader | |
| from ignite.engine import Engine, Events |