This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| {{FrontSide}} | |
| <hr id="answer"> | |
| {{answer}} | |
| <div id="search-container"> | |
| <a class="search" id="bing-img-search" href="https://www.bing.com/images/search?safeSearch=Strict&setLang=en&mkt=en-US&q={{text:word}}&tsc=ImageBasicHover&qft=+filterui:license-L1"> | |
| Bing | |
| </a> | |
| | |
| <a class="search" href="https://www.google.co.jp/search?q={{text:word}}&tbm=isch"> |
t9md
/ 0-音読21日チャレンジ リンク.md
Last active
January 14, 2021 23:27
- HOW TO DECLUTTER YOUR MIND
- 4 WAYS TO UPGRADE WORKDAY
- THREE MENTAL BLOCKS
- IT'S TIME FOR YOU TO TRACK YOUR TIME
- DON'T HAVE A PASSION? THAT'S OKAY
- ADVICE FOR WRITERS
- 6 PRODUCTIVITY HACKS
- DO THIS BEFORE TRYING PRODUCTIVITY HACKS
- [HOW TO SPLIT CHORES WITH YOUR PARTNER](https://ideas.ted.com/how-to-split-the-chores-with-your-partner-minus-the-drama-and-fighting
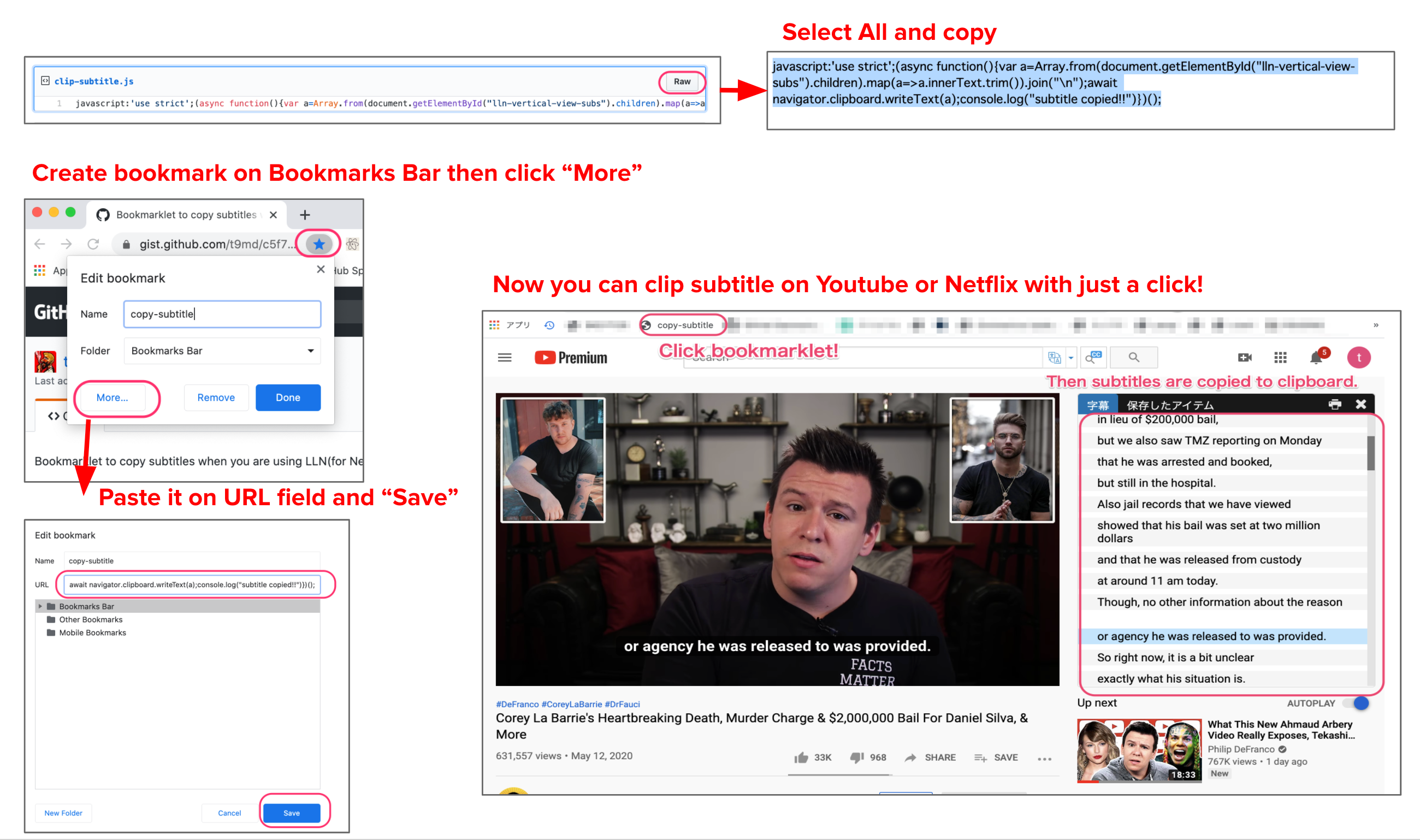
This bookmarklet works for both LLN and LLY.
- Create bookmark on bookmarkbar with the name
copy-subtitle. - Edit bookmark you've just created and replace
URLwith content of clip-subtitle.js. - On Yourtube with LLY enabled, click bookmarklet. Done.
- Now, you have subtitles in your clipboard. So you can paste it to DeepL
If you want to modify bookmarklet.
t9md
/ 英語の言語習得。雑感
Created
June 19, 2019 06:50
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| - リスニング能力は総合力。ここが本当の実力 | |
| - スピーキングは大分後回しで良い、勝手にレベルアップする(という理論、事例が多数あり) | |
| - 何故かと言うと、自然に喋れるためには Grammar intuition と パターン蓄積が必須だが、これは大量Inputによって得られるから。 | |
| - 常にスピーキング能力はリスニング能力より下になる。これは当たり前の話。日本語でもそうだよね? | |
| - パターン蓄積とは、特定の事言いたい場合の言い方の例を溜めること。 例: お腹空いた vs I am hungry | |
| - なので、大量のリアルな音声インプットが必須 | |
| - このとき、50%しか、あるいは20%しか分からなかったとき、それで完璧主義/潔癖主義に陥らないこと。 | |
| - 曇った眼鏡でも楽しめるはず。そして続けていれば20%→21%になる。それはレンズの曇りが晴れてより楽しめるようになる。 | |
| - こういう姿勢で臨めば自分が興味がある分野の動画/音声を、"楽しんで毎日聞き続ける"(お勉強ではなく)ことが可能になる。 | |
| - 楽しめる→継続できる→慣れる→解像度が上がる(キャッチできる部分が増える)→より楽しめる→勝手に少しずつレベルアップする |
t9md
/ copy_reduced_image.rb
Created
February 17, 2019 15:30
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| def copy_reduced_image(file) | |
| puts "#### #{file}" | |
| File.readlines(file).each do |line| | |
| word = line.split("\t")[0] | |
| cmd = "ffmpeg -y -i slideshow/imgs/#{word}.png -vf 'scale=1334:-1' -q 2 icloud-app/imgs/#{word}.png" | |
| system cmd | |
| # puts cmd | |
| end | |
| end |
t9md
/ audioAPI-example.js
Created
February 7, 2019 09:21
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| window.AudioContext = window.AudioContext || window.webkitAudioContext | |
| class AudioPlayer { | |
| constructor () { | |
| this.context = new AudioContext() | |
| } | |
| // Audio 用の buffer を読み込む | |
| getAudioBuffer (url, callback) { | |
| const req = new XMLHttpRequest() | |
| req.responseType = 'arraybuffer' // array buffer を指定 |
help
$ ruby extract-fields.rb -h
Usage: extract-fields [options]
-r, --report Report field configuration from very 1st line. (default: false)
-s, --split VALUE string value (default: "\t")
-j, --join VALUE string value (default: "\t")
-f, --fields one,two,three fields to extract (default: [])
t9md
/ batch-image-retrieve.py
Created
January 30, 2019 11:23
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| # -*- coding: utf-8 -*- | |
| import sys | |
| import os | |
| from selenium import webdriver | |
| from selenium.webdriver.common.action_chains import ActionChains | |
| def save_snapshot(driver, word): | |
| fname = 'imgs/%s.png' % word |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| // get tree sitter supported grammar | |
| atom.grammars.treeSitterGrammarsById |
NewerOlder