Efficient Estimation of Word Representations in Vector Space (2013 Sept) link Distributed Representations of Words and Phrases and their Compositionality (2013 Oct) link
GloVe: Global Vectors for Word Representation (2014 Jan) link
The Text2Shape task:
A note for sentence/doc embeddings: Summary for sentence/doc embeddings
This note briefly introduced three statistical learning methods in NLP applications: the latent dirichlet allocation for topic modeling, the conditional random fields for named entity recognition and matrix factorization for latent semantic analysis.
Dirichlet distribution is a multivariate generalization of the beta distribution.

A general definition of representation: transform the origin data(word/sentence/doc, or even images) to vectors that contain information and useful as input for models.
Similar word/sentence/doc tend to be close to each other measured by cosine distance. (map the origin data to a meaningful vector space) It's nice-to-have but not a must. This feature is useful for tasks like semantic similarity comparison, clustering, and information retrieval via semantic search.
Examples for representations with/without the cos similarity feature: Word2vec provides the cos similarity feature for word embeddings, and furthermore it preserve linear regularities among words (vector(”King”) - vector(”Man”) + vector(”Woman”)). But average/last embeddings from BERT don't guaranteed the cos similarity feature, and thus have a bad performance when you apply cosine distance directly to measure sentence/doc similarity (even worse than sentence embeddin
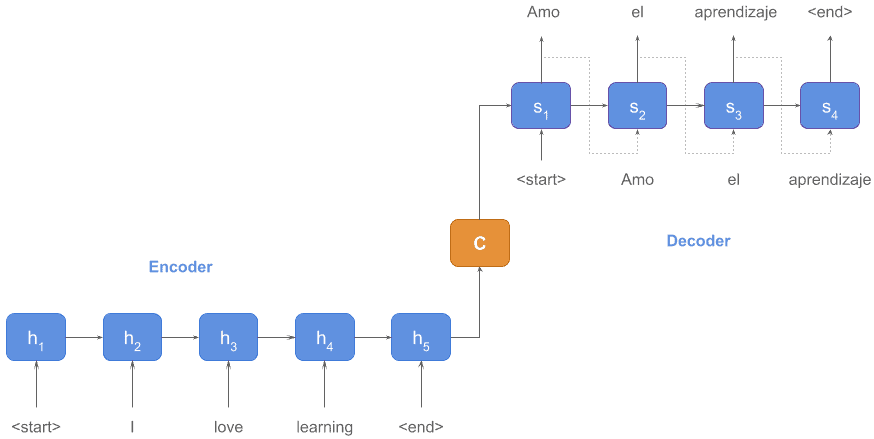
As the word embeddings, for sentences and articles, there are sequence auto-encoder models, which turn the text into a vector representation, and sequence auto-decoder models, which unfolded a vector representation and returned something meaningful like text, tags, or labels.
In the famous paper "Attention Is All You Need" published in 2017, the researchers in Google proposed Transformer, a encode-decode model only with attension mechanism. Before this paper, there were already many former works about neural network encoder and decoder. However, unlike the Transformer that based solely on attention mechanisms, most of the former encoders/decoders relied on recurrent or convolutional structure. Compared with 1-dimension CNN that can only focus on fixed-length parts of the sentence sequences due to the limitation of convolution kernels, attentionism as the weighted average can handle the whole sentence s
Before starting the discussion, go through the following three questions:
With vim,