As the word embeddings, for sentences and articles, there are sequence auto-encoder models, which turn the text into a vector representation, and sequence auto-decoder models, which unfolded a vector representation and returned something meaningful like text, tags, or labels.
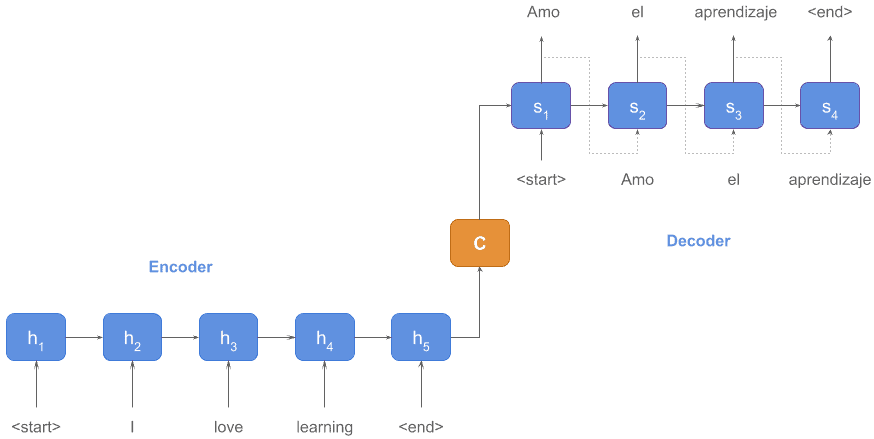
In the famous paper "Attention Is All You Need" published in 2017, the researchers in Google proposed Transformer, a encode-decode model only with attension mechanism. Before this paper, there were already many former works about neural network encoder and decoder. However, unlike the Transformer that based solely on attention mechanisms, most of the former encoders/decoders relied on recurrent or convolutional structure. Compared with 1-dimension CNN that can only focus on fixed-length parts of the sentence sequences due to the limitation of convolution kernels, attentionism as the weighted average can handle the whole sentence sequences and thus it's far more flexible. Compared with RNN that widely used in the sequence model, Transformer is parallel-friendly, due to the minimum number of sequential operations required, and thus could have an advantage over RNN structure on large datasets.
Since Transformer is more parallelizable and requiring significantly less time to train, it's suitable to be used as a pre-trained model on huge datasets. The following works include BERT and GPT, which achieved great success in general natural language tasks. Besides, by visualization on attention weights, Transformer could provide insights for the neural networks, yielding more interpretable models.

BERT stands for Bidirectional Encoder Representations from Transformers. It's a pre-trained model that can be fine-tuned to create state-of-the-art models for a wide range of tasks, such as text sentiment analysis and summarization, without substantial task-specific architecture modifications. Compared to other transformer-based models like OpenAI GPT, BERT has a bidirectional network structure that jointly conditioned on both left and right context in all layers.

Pre-training for language representations bidirectionally could improve the transformer model performance significantly. BERT achieved the bidirectionality by introducing two pre-training objective, Masked Language Model(Cloze) and Next Sentence Prediction. The Masked Language Model randomly masks some of the tokens from the input, and the objective is to predict the original vocabulary id of the masked word based only on its context. Unlike left-to-right language model pre-training, the MLM objective enables the representation to fuse the left and the right context, which allows us to pre-train a deep bidirectional Transformer. However, Masked Language Model could not directly captured the relationship between two sentences, which is important for more complex downstream tasks such as Question Answering(QA) and Natural Language Inference(NLI), so the Next Sentence Prediction pre-training objective was introduced as a supplement.

After pre-training on unlabeled data, the BERT was fine-tuned to model a broad range of downstream tasks. For fine-tuning, we combined the BERT model with just one additional output layer, initialized BERT with the pre-trained parameters, and fine-tune all of the parameters using labeled data from the downstream tasks. Benefitting from rich, unsupervised pre-training BERT enables even low-resource downstream tasks.
BERT outperformed other state-of-the-art models like BiLSTM+ELMo+Attn and GPT on GLUE benchmark, which including tasks such as semantic textual similarity, text sentiment analysis, natural language inference, textual entailment recognition and question answering.