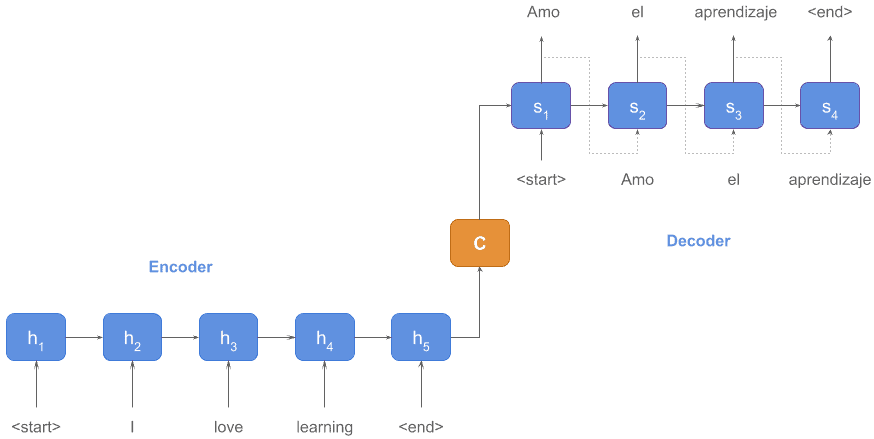
As the word embeddings, for sentences and articles, there are sequence auto-encoder models, which turn the text into a vector representation, and sequence auto-decoder models, which unfolded a vector representation and returned something meaningful like text, tags, or labels.

In the famous paper "Attention Is All You Need" published in 2017, the researchers in Google proposed Transformer, a encode-decode model only with attension mechanism. Before this paper, there were already many former works about neural network encoder and decoder. However, unlike the Transformer that based solely on attention mechanisms, most of the former encoders/decoders relied on recurrent or convolutional structure. Compared with 1-dimension CNN that can only focus on fixed-length parts of the sentence sequences due to the limitation of convolution kernels, attentionism as the weighted average can handle the whole sentence s