Blog 2020/6/10 (retroactively blogged on 2020/6/12)
<- previous | index | next ->
LuaJIT is an amazingly fast implementation of Lua which uses just-in-time compilation.
On their website, they use a number of benchmarks to compare the performance boost of their JIT'ed implementation vs. the stock Lua interpreter.

However, they don't present the information in a way which makes it easy to see the performance differences between architectures.
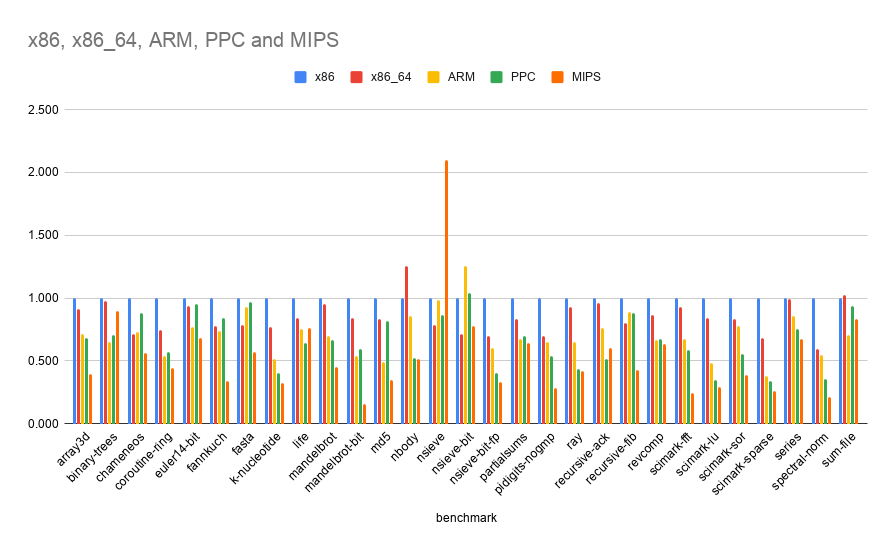
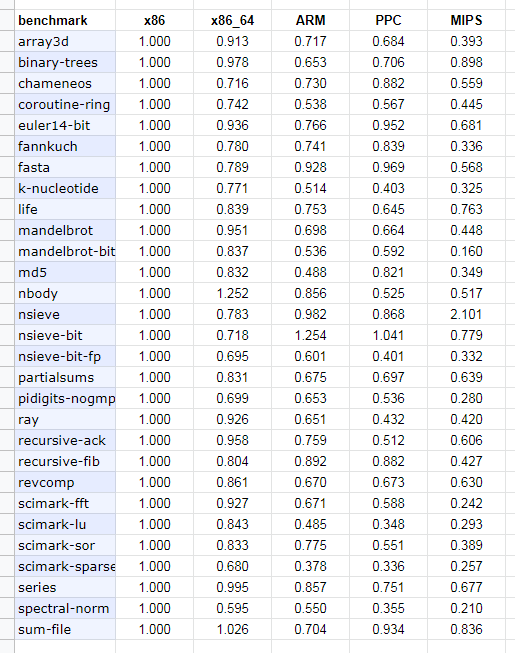
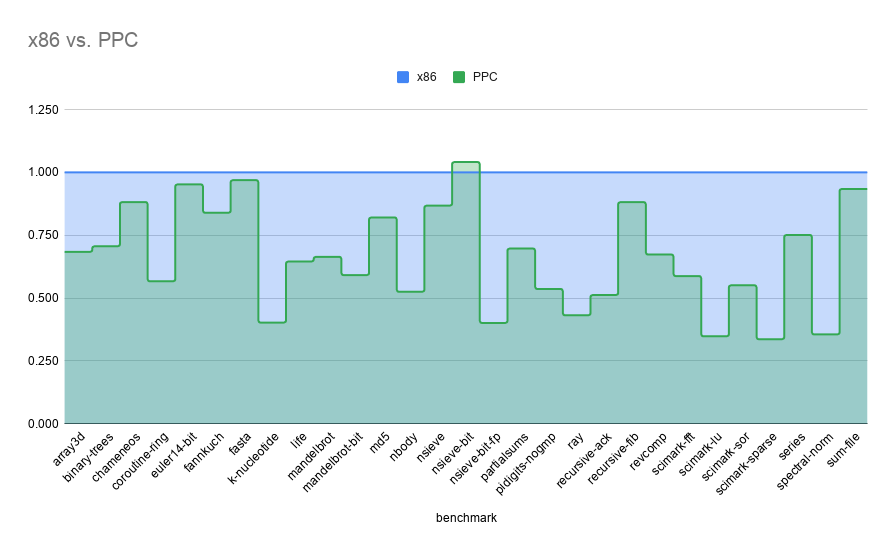
I copied their numbers into a spreadsheet, normalized each benchmark, and then graphed each architecture against x86.
In most cases, the JIT performance boost isn't quite as large on other architectures.
Note: these are comparisons of JIT boost, not comparisons of absolute performance. If the graph indicates 50%, that means that architecture's JIT sees only 50% of the speedup seen by the x86 JIT over the stock Lua interpreter.
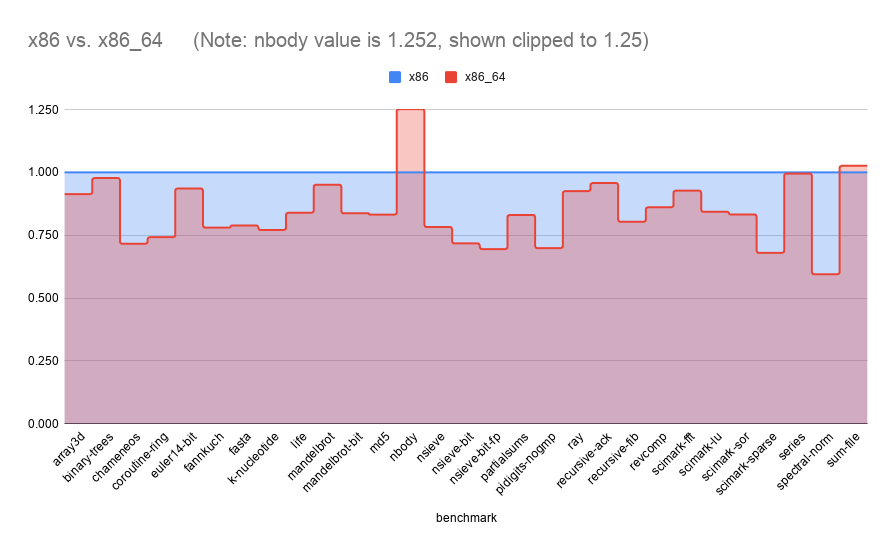
I was surprised to see that x86_64 generally doesn't see as much of a JIT boost as x86 (with the exception of nbody).
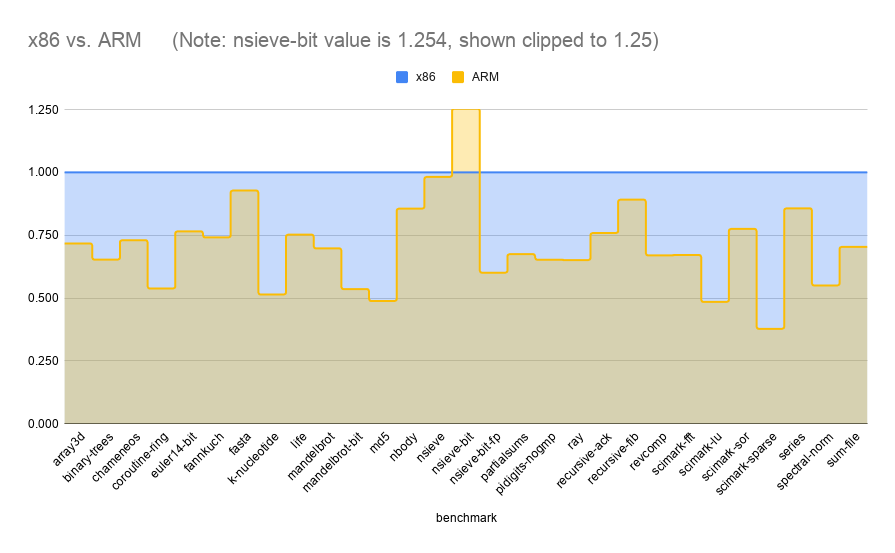
ARM sees a slightly smaller speedup than x86_64 (with the exception of nsieve-bit).
PowerPC sees a yet smaller boost, sometimes dipping below 50% of x86's JIT boost.
MIPS sees a still smaller boost overall, with the exception of an extreme outlier: nsieve sees over twice the speedup of x86.

The MIPS graph with nsieve clipped: