-
-
Save heejongahn/00d68a40415613893ad0 to your computer and use it in GitHub Desktop.
| 우하하 |
Memory Hierachy: Cache Basics
Memory Hierarchy
Memory Technology
- Static RAM : 매우 빠르지만 컴포넌트가 많아 density 떨어짐. cost per byte 매우
높다. 전력 소모 큼. - Dynamic RAM : dense 하지만 상대적으로 느리다.
- Magnetic disk : 매우 느리고 엄청나게 싸다
우리는 SRAM의 속도와 자기 디스크의 가성비를 가진 저장 장치를 원한다. 도둑놈 심보
Memory Hierarchy Technology
- SRAM for cache : speed, tech compatibility
- DRAM for main memor : 보다 느리지만 괜찮은 속도, 높은 밀집도. 주기적으로
capacitor를 refresh 시켜줘야 한다.
Processor-Memory Performance Gap
Microprocessor의 성능은 무어의 법칙에 따라 18개월마다 2배 정도의 성장세를 보이는데,
메인 메모리 성능은 그 성장세를 전혀 못 따라가고 있다.
우리의 pipeline design은 메모리 접근에 1 cycle access로 충분하다고 가정하지만,
실제로 main memory access time은 200 cycle 정도.
Hierarchy + parallelism = The illusion of large, fast and cheap memory!
Locality
Locality
Locality
정말 중요하니까 세 번 썼다. 이걸 이용해서 위에서 말한 환상을 만들어냄.
- register <-> memory : 컴파일러가 관리
- cache <-> main memory : 캐시 컨트롤러 HW가 관리
- main memory <-> disk : OS가 관리 (가상 메모리) w/ TLB
Locality
- Temporal (time)
- Spatial (space)
뭔지는 다 알거라 믿는다. 얼마나 locality를 잘 살린 프로그램을 짜느냐는 1차적으로프로그래머의 몫.
Terminology
- Block
- Hit Rate, Hit Time (블락까지 가는 시간 + Hit인지 판별하는 시간)
- Miss Rate, Miss Penalty (Miss일 때 갈아끼는 시간)
Example
70% hit rate, cache hit 1 cycle, main memory access 25 cycle.
Average memory access time = Hit Latency + Miss rate * Miss Latency = 1 + (0.3) * 25 = 8.5
Cache Basics
- 찾는 데이터가 캐시에 있는가?
- 있다면, 캐시 속 어디에 있는가?
Direct Mapping : memory block은 단 하나의 cache block에만 매핑 된다. 주소의 upper portion을 캐시 테이블의 인덱스로 사용.
Basic Structure
concrete (multiword) example: 4B word, 4KB cache, 16B per line
32-bit address -> 2-bit byte offset + 2-bit block offset + 8-bit index + 20-bit
tag
- Direct Mapped Cache : Temporal locality
- Multiword Block Direct Mapped Cache : Temporal + Spatial locality
Tradeoffs
Block size가 커질 때
- Spatial locality 증가
- 블락 개수가 줄어듬 -> more competition
- miss penalty가 커짐 (더 큰 블락을 가져와야 함)
블락 사이즈가 커짐에 따라 miss rate는 줄어들다가 어느 수준을 넘어서면 커짐. 너무큰 블락 사이즈로는 캐시에 블락이 몇 개 밖에 못 올라와있음.
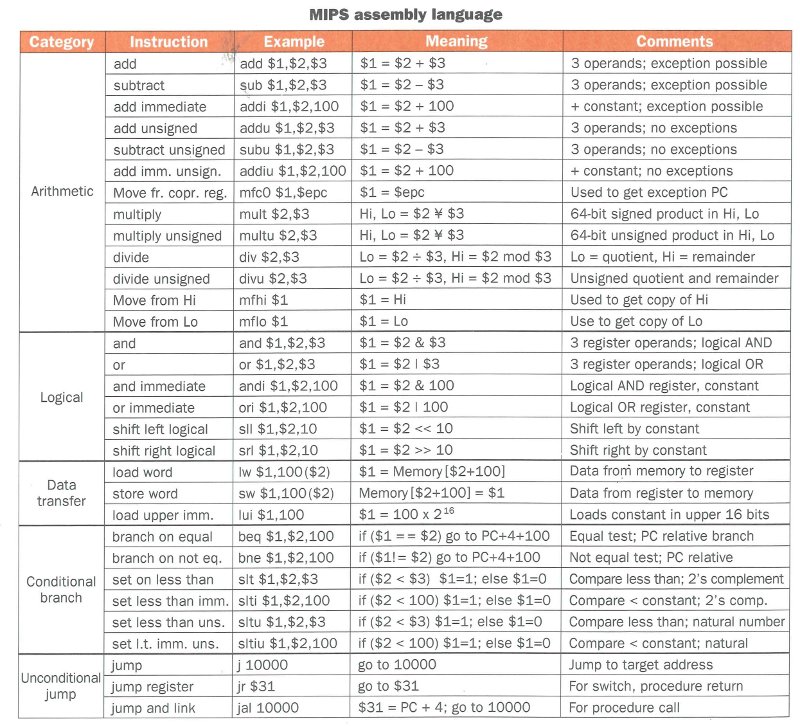
Instruction Set Architectue I
Instruction Set Architecture
Contract between programmer and the HW
- 프로그래머 : 프로그램이 어떻게 실행될지에 대한 모델
- HW 디자이너 : 프로그램을 올바르게 실행하는 방법에 대한 formal definition
우리는 MIPS를 사용할거야.
Two Key Principles
- 인스트럭션이랑 데이터 구분 불가
- 데이터처럼 프로그램도 메모리에 올라감
state -> formatted instruction -> another state
Design principle 1: Siplicity favors regularity
MIPS-32 ISA
Arithmetic Instructions
instruction rd, rs, rt -> rd = rs (instruction) rt
formatted as opcode | rs | rt | rd | shamt | function
f = (g + h) - (i + j);
MIPS (pseudo)코드로 쓰면
add t0, g, h
add t1, i, h
sub f, t0, t1
MIPS는 Big Endian : MSB가 가장 낮은 주소에!
Design principle 2: Smaller is faster
MIPS Register File
32개의 32-bit register가 들어있음. 2개의 읽기 포트, 1개의 쓰기 포트.
레지스터의 특징
- 메인 메모리보다 빠르다. 이 때 레지스터 개수 혹은 포트수가 늘어나면 느려짐
- 컴파일러가 사용하기 쉽다
- 변수를 여기 저장하면 코드 밀집도가 증가함 (메모리 주소보다 적은 공간 차지)
Types of operand
- Register operand: $0(zero), $5, ... -> 매우 빠르다
- Memory operand: offset(base register) = (base register 값 + offset) 위치에 있는 데이터
- immediate openand: 상수값. 작은 상수들은 자주 쓰이니까 이걸 이용해서 계산하렴.
Design principle 3: Make the common case fast
zero register($0) 상수 0으로 고정. 레지스터간 값 이동등에 사용하렴.
signed extension, unsigned integer, 2's complement -> 생략
MIPS Instruction formats

Design principle 4: Good design demands good compromises
Instructions
If statement
if (i==j) f = g+h;
else f = g-h;
f가 $4에, g가 $5에, h가 $6에 있다 치면
bne $5, $6, Else
add $4, $5, $6
j Exit
Else: sub $4, $5, $6
Exit: ...
Loop statement
while (save[i] == k) i += 1;
i가 $3에, k가 $5에, save의 주소가 $6에 있다 치면
Loop: sll $1, $3, 2
add $1, $1, $6
lw $2, 0($1)
bne $2, $5, Exit
addi $3, $3, 1
j Loop
Exit: ...
Basic blocks
브랜치나 브랜치 타겟 없이 무조건 같이 실행되는 블락. 컴파일러는 최적화를 위해
basic block을 구분한다.
Why not blt, bge, ...?
-> 대소 비교를 위한 HW가 같은지 아닌지 비교하는 애보다 훨씬 느리다. Faster
common cases!
Instruction Set Architecture II
Procedure call
메모리 중 Stack에 쌓인다. 각 프로시져 콜은 stack frame을 형성한다. 이 때
stack frame의 형성 및 제거는 stack pointer(SP)를 움직여서 구현. 스택은 높은
주소에서 낮은 주소로 자란다.
Six steps
- 메인 루틴(caller)가 프로시져(callee)가 접근 할 수 있는 위치(argument
register)에 파라미터들을 위치시킴 - caller가 callee에게 제어권을 넘긴다.
- callee가 필요로 하는 storage resource를 획득
- callee가 해야 할 일을 한다
- callee가 리턴 값을 value register에 위치시킴
- callee가 제어권을 caller에게 넘긴다.
Instructions used
jal ProcedureAddress # jump and link
PC+4 를 리턴 주소로 $ra에 저장한 뒤 target address로 점프.
jr $ra # return

만약 callee가 사용해야 할 레지스터가 4개 이상일 경우에는 어떻게 해야할까요? 이에
우리 제작진은, 스택을 사용하기로 했습니다.
$sp = $sp - 4 # before push
$sp = $sp + 4 # after pop
Examples
Leaf Procedure
int leaf(int g, h, i, j) {
int f;
f = (g + h) - (i + j);
return f;
}
leaf:
# 스택에 $s0 저장
addi $sp, $sp, -4
sw $s0, 0($sp)
# $s0 = (g + h ) - (i + j)
add $t0, $a0, $a1
add $t1, $a2, $a3
sub $s0, $t0, $t1
# return $s0
add $v0, $s0, $zero
# $s0값과 스택 복원
lw $s0, 0($sp)
addi $sp, $sp, 4
# 리턴
jr $ra
Non-leaf Procedure
int fact (int n) {
if (n < 1) return 1;
else return n * fact(n - 1);
}
fact:
# 스택에 n 이랑 return address 저장
addi $sp, $sp, -8
sw $ra, 4($sp)
sw $a0, 0($sp)
# 조건(n < 1) 확인, 아닐 경우 L1으로 점프
slti $t0, $a0, 1
beq $t0, $zero, L1
# n < 1이면 리턴값 1
addi $v0, $zero, 1
addi $sp, $sp, 8
jr $ra
L1:
# n-- 한 뒤 recursively call fact
addi $a0, $a0, -1
jal fact
# $a0 = n, $ra = 리턴 주소, 스택 복원
lw $a0, 0($sp)
lw $ra, 4($sp)
addi $sp, $sp, 8
# 리턴값 = n * fact(n-1)
mul $v0, $a0, $v0
# 리턴
jr $ra
Memory Layout
- Text: 프로그램 코드
- Static data: 전역 변수
- Dynamic data: heap
- Stack: automatic storage
Byte/Halfword Operations
- lb, lh: sign extended
- lbu, lhu: zero extended
- sb, sh: store only rightmost portion
Memory Addressing Mode
MIPS는 displacement mode (offset(base)) 형태만 지원합니다. 만세~
String copy
void strcpy (char x[], char y[]) {
int i;
i = 0;
while ((x[i]=y[i]) != '\0')
i += 1;
}
x, y의 주소가 각각 $a0, $a1에 있고 i가 $s0에 있다면
strcpy:
# Stack increment
addi $sp, $sp, -4
# Save $s0, $s0 = 0
sw $s0, 0($sp)
add $s0, $zero, $zero
L1:
# $t1 = address of y[i], $t2 = y[i]
add $t1, $s0, $a1
lbu $t2, 0($t1)
# t3 = address of x[i], x[i] = y[i]
add $t3, $s0, $a0
sb $t2, 0($t3)
# if y[i] == 0, jump to L2
beq $t2, $zero, L2
# i++
addi $s0, $s0, 1
j L1
L2:
lw $s0, 0($sp)
addi $sp, 4
jr $ra
la (32-bit)
lui + ori
Branch addressing
Target address = next instruction's PC + 4 * offset
Jump Addressing
Target address = lower 28 bit / 4
Swap
void swap[int v[], int k) {
int temp;
temp = v[k];
v[k] = v[k+1];
v[k+1] = temp;
}
v in $a0, k in $a1, temp in $t0
swap:
# t1 is address of v[k]
sll $t1, $a1, 2
add $t1, $a0, $t1
#swap
lw $t0, 0($t1)
lw $t2, 4($t1)
sw $t2, 0($t1)
sw $t0, 4($t1)
ja $ra
non-leaf는 피피티 보자..
Object
Object module 생성
- 어셈블러가 프로그램을 machine instruction으로 바꿈
- 전체 프로그램을 만들기 위해 필요한 정보 담아야 함
- 헤더
- 텍스트 영역
- 스태틱 데이터 영역
- relocation info: 합쳐진 후에 정해질 수 있는 정보들 (ex 외부 파일에 정의된
녀석의 주소) - symbol table: 전역변수나 external ref 이름과 값 매치
- debug info
링킹
- segment들을 합친다
- label들에 실제 주소를 할당한다
- location-dependent, eternal refs에 올바른 값을 집어넣는다
로딩
- 헤더를 읽고 사이즈 판단
- 가상 주소공간 생성
- text 영역 복사, data 초기화
- 스택에 인자들 세팅
- 레지스터 초기화
- startup routine으로 점프
Instruction Set Architecture III
RISC vs CISC
- RISC 장점 : 간단한 구현, 공간 및 전력 절약, 파이프라이닝 특화
- CISC 장점 : 코드 밀집도, 호환성
RISC의 특징:
- hardwired control
- load-store machine
- few addressing modes
- fixed-size instruction
- rely on compiler optimization
대표적 CISC인 x86: variable length encoding... 실질적으로는 microengine을 이용해
microoperation들로 쪼개서 사용
오해
강력한 인스트럭션 -> 고성능?
인스트럭션 수는 적겠지만 구현이 어렵다. 또한 컴파일러가 머리 터진다. 아마 clock
cycle time도 늘어나야 할듯?
어셈코드로 짜면 고성능?
컴파일러가 너보다 똑똑할걸...
backward compatibility를 위해선 인스트럭션 셋이 고정되어야 한다
추가시키는건 괜찮아!
Compilation
source code -> tokens -> abstract syntax tree
Forward Reference
- arithmetic / logical / shift 등은 인스트럭션 내에 필요한 정보 다 있음
- branch는 pc-relative
- 라벨들의 위치를 알기 위해서는 어셈블리 코드를 두 번 읽어야 한다. 플젝 해봤지?
- jump는 절대주소 필요로 함. 링킹 마친 후에 할 수 있음.
Symbol Table
- 다른 파일에서 사용될 수 있는 "item"들에 대한 정보 저장
- label for function call
- data
Relocation Table
- 지금은 주소를 알 수 없는 "item"들에 대한 정보 저장
- j / jal 레이블
- static section의 데이터
링커
- input: object code files, information tables
- output: 실행가능 코드
여러 오브젝트 파일을 하나의 실행가능 코드로 엮어준다.
이 때
relocated text1 | relocated tex2 | relocated data1 | relocated data2
가 최종 포맷이 된다.
스텝 바이 스텝
- 각 오브젝트 파일에서 text segment 뽑아내서 합침
- 각 오브젝트 파일에서 data segment 뽑아내서 합친 뒤에 text 뒤에 붙임
- relocation table 보면서 각 항목들에 해당하는걸 절대주소로 채움
이 때
- text segment는 0x400000으로 가정
- 링커는 각 데이터, 텍스트 섹션의 길이를 알고 있음
- 절대주소 계산 알아서 잘
Pipeline Control Hazard
Control Hazard
인스트럭션 주소가 sequential하게 (PC = PC + 4) 흐르지 않을 때 발생.
가능한 해결책들
데이터 해저드의 forwarding 처럼 무조건 좋은 녀석은 없다.
Unconditional branch
ID(Decoding) stage 가 지나야 jump 임을 알 수 있음
-> 하나의 flush가 필요함. IF.Flush = 0 (j 바로 다음 인스트럭션을 noop으로 만듬)
두 종류의 Stall
Conditional branch
Flushing
가 있다고 해보자. beq의 타겟 주소는 MEM stage 이후에 알 수 있으므로 3개의
인스트럭션을 flush 해야 함 -> CPI에서 심각한 손해를 봄.
Early decision
만약 ID 혹은 EX stage 에서 branch target을 알 수 있다면 그만큼 적은 stall을
필요로 한다.
이 때 추가적인 HW compent (mux, AND gate, adder, ...) 들을 필요로 함.
ID Branch Forwarding Issues
앞의 단계에서 branch target 계산을 위해서는 앞의 인스트럭션에서의 결과값을
넘겨줘야 할 때가 있다.
이 때, branch instruction이 execute 되는 시점에서 올바른 값을 갖고 있음이 보장되어야
한다. 만약 직전 인스트럭션의 rd가 branch target을 결정하는 레지스터 중 하나라면
stall이 필요하다.
Static Branch Prediction
정적으로 분기를 예측해보자.
Predict not taken
항상 분기가 택해지지 않는다고 가정하고 sequential 한 인스트럭션들을 fetch.
보동 top of the loop branching structure 에서 잘 동작한다. (끝까지 내려간 뒤에
맨 위로 j하고 beq 일시 break하는 구조)
bottom of the loop branching structure 에서는 잘 동작하지 않는다.
Predict taken
항상 1개의 stall cycle이 존재한다.
Dynamic Branch Prediction
IF stage에 BHT(branch history table)이 존재, 어떤 주소의 branch가 지난 실행에서

택해졌는지 아닌지에 대한 정보를 갖고 있다. 이 prediction은 틀려도 correctness에는
영향을 주지 않고 performance 만 깎아먹음.
Branch Target Buffer
BHT로는 branch take 여부만 알 수 있지, target을 알 수 없다.
따라서 IF stage cache에 branch target buffer(BTB)를 둬서 branch target address를
저장. Two read port instruction memory 가 필요하다.
2-bit Predictor
2번 틀려야만 예측 방향을 바꾸게 한다.
Exceptions
다양한 소스에서부터 오는 예외들을 어떻게 처리해줘야 할까? 크게 다음과 같이 두
종류로 나눌 수 있다.
I/O service requets, HW malfunction, ...
Arithmetic overflow, Undefined instruction, ...
single clock cylce 내에서도 여러 예외가 동시에 일어날 수 있다. 이 때 HW가 알아서
소팅해준 뒤에 가장 먼저 fetch 된 인스트럭션의 예외부터 처리한다.
HW