-
-
Save mirko77/3f4a101cd4a77e2ae3e760d44d18d901 to your computer and use it in GitHub Desktop.
| library(httr) | |
| library(jsonlite) # if needing json format | |
| cID<-"999" # client ID | |
| secret<- "F00HaHa00G" # client secret | |
| proj.slug<- "YourProjectSlug" # project slug | |
| form.ref<- "YourFormRef" # form reference | |
| branch.ref<- "YourFromRef+BranchExtension" # branch reference | |
| res <- POST("https://five.epicollect.net/api/oauth/token", | |
| body = list(grant_type = "client_credentials", | |
| client_id = cID, | |
| client_secret = secret)) | |
| http_status(res) | |
| token <- content(res)$access_token | |
| # url.form<- paste("https://five.epicollect.net/api/export/entries/", proj.slug, "?map_index=0&form_ref=", form.ref, "&format=json", sep= "") ## if using json | |
| url.form<- paste("https://five.epicollect.net/api/export/entries/", proj.slug, "?map_index=0&form_ref=", form.ref, "&format=csv&headers=true", sep= "") | |
| res1<- GET(url.form, add_headers("Authorization" = paste("Bearer", token))) | |
| http_status(res1) | |
| # ct1<- fromJSON(rawToChar(content(res1))) ## if using json | |
| ct1<- read.csv(res1$url) | |
| str(ct1) | |
| # url.branch<- paste("https://five.epicollect.net/api/export/entries/", proj.slug, "?map_index=0&branch_ref=", branch.ref, "&format=json&per_page=1000", sep= "") ## if using json; pushing max number of records from default 50 to 1000 | |
| url.branch<- paste("https://five.epicollect.net/api/export/entries/", proj.slug, "?map_index=0&branch_ref=", branch.ref, "&format=csv&headers=true", sep= "") | |
| res2<- GET(url.branch, add_headers("Authorization" = paste("Bearer", token))) | |
| http_status(res2) | |
| ct2<- read.csv(res2$url) | |
| # ct2<- fromJSON(rawToChar(content(res2))) ## if using json | |
| str(ct2) |
Hi @mirko77 - I was just wondering where I could find the 'project.slug' and 'form.ref' information from Epicollect? I'm guessing those respond to the name at the end of the project URL (https://five.epicollect.net/project/project.slug) and the form name in the Form Builder, respectively? I'm able to retrieve the token successfully when I run the code above, but get errors with the part of the code beginning with 'url.form:'
http_status(res1)
$category
[1] "Client error"
$reason
[1] "Bad Request"
$message
[1] "Client error: (400) Bad Request"
Any thoughts on what could be causing this?
Thanks,
Jay
@jaymwin - if you click on the 'Details' button associated with any of your EpiCollect projects, you should see an 'API' link on the left of the page that then opens. Click 'API' and you will then see the parameters you are after.
@schafnoir answer is correct.
If you have only one form, the form ref parameter is not even needed, as it will default to the first form anyway.
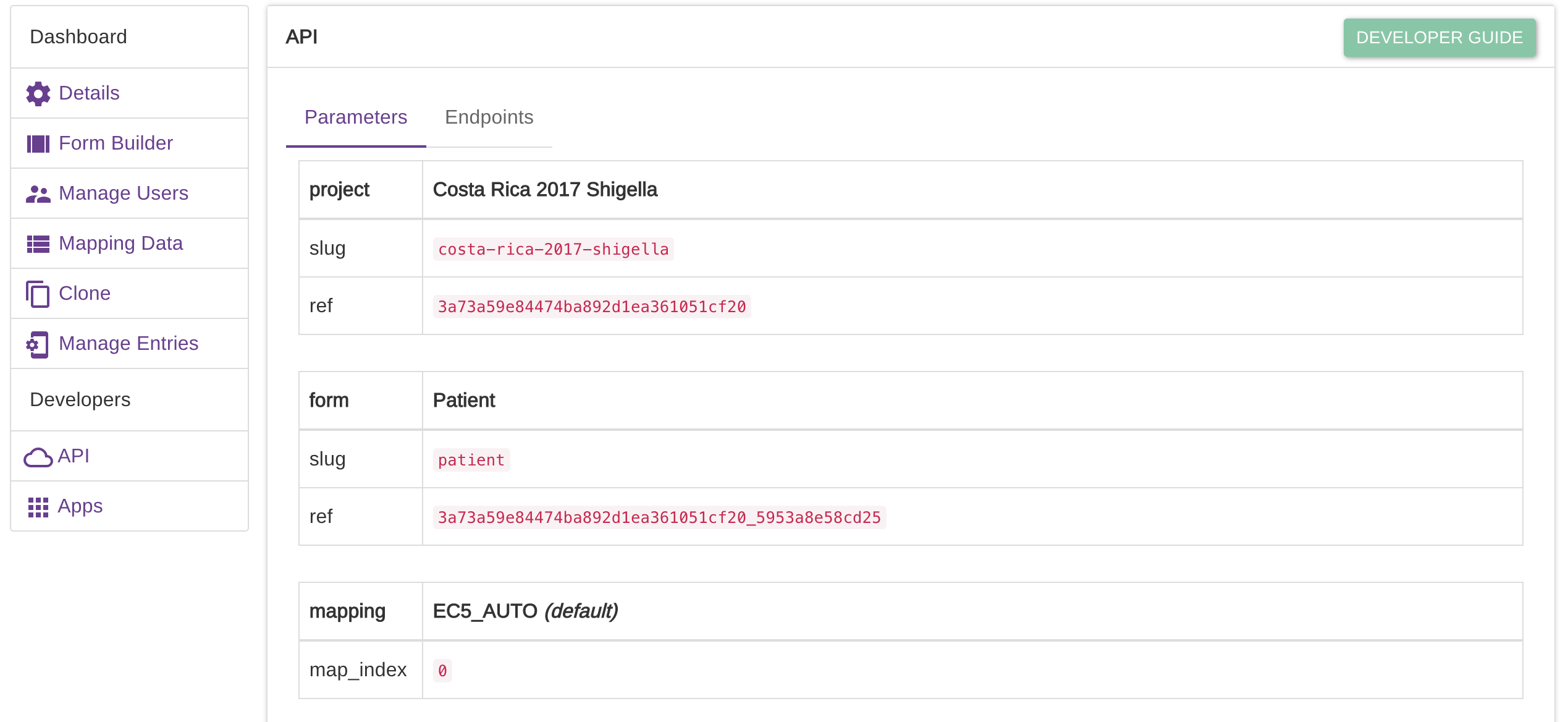
thanks @schafnoir and @mirko77 - using those parameters and removing form.ref here did the trick:
url.form<- paste("https://five.epicollect.net/api/export/entries/", proj.slug, "?map_index=0&form_ref=", "&format=csv&headers=true", sep= "")
hey,
I am trying to set up an automated transfer of pics to my drive using AWS. Some days back it was working fine and it seems like it broke in the meantime. The problem is that it is not downloading original files but just the file that is named the same but has only 77B of information for each file. Any ideas? I have used the same code as presented above.

Tried it again:

The code:
for( pic in pics){
imageURL <- paste0("https://five.epicollect.net/api/export/media/", proj.slug, "?type=photo&format=entry_original&name=", pic)
httr::GET(
imageURL,
add_headers("Authorization" = paste("Bearer", token)),
write_disk(
path = here("dta/img/", pic),
overwrite = TRUE)
)
## Upload on Google drive
# googledrive::drive_upload(media = here("dta/img/", pic),
# path = folder_id$id
# )
## Remove from local folder
# file.remove(here("dta/img/", pic))
Sys.sleep(2)
}
Example image URL is:
"https://five.epicollect.net/api/export/media/soyscout?type=photo&format=entry_original&name=7149429a-3eb3-4999-b106-d836090e6b59_1652127690.jpg"
We have no experience of AWS we afraid.
It looks like your requests get capped at 78b, so they are either wrong or you are over a quota (30 requests per minute for media files on our API =>https://developers.epicollect.net/#rate-limiting). You might want to catch any network errors as well. The 78b might be the error response, which you are saving as an image regardless of its content.
Is the access token valid? They expire every 2 hours. https://developers.epicollect.net/api-authentication/retrieve-token
You could try the Javascript example here, probably easier to debug things -> https://developers.epicollect.net/examples/getting-media
There is a fiddle to play with as well https://jsfiddle.net/mirko77/y45brprq/
Apologies for the delay- it was an error message. I would imagine it was happening because of too many calls when I was developing this as it disappeared once I left it all for a day or two and added time breaks between API calls. Thank you!
Great, I am glad the issue is solved!
That is interesting. I used exactly the code from above. The Jason one works fine. But the CSV one works fine until the ct1<- read.csv(res1$url).
@jimer666 I am facing the same issue you had, I am able to get the entries in the JSON format but the csv does not work. Were you able to resolve this issue?
Thank you
This line gives the error
ct1<- read.csv(res1$url)
Error in file(file, "rt") : cannot open the connection
That is exactly what I did. I tried using Python, which works fine. I used exactly the code from above, the Jason one works fine but the CSV one showed error until the ct1<- read.csv(res1$url).