Motoki Wu tokestermw
Apologies for the snarky title, but there has been a huge amount of discussion around so called "Prompt Engineering" these past few months on all kinds of platforms. Much of it is coming from individuals who are peddling around an awful lot of "Prompting" and very little "Engineering".
Most of these discussions are little more than users finding that writing more creative and complicated prompts can help them solve a task that a more simple prompt was unable to help with. I claim this is not Prompt Engineering. This is not to say that crafting good prompts is not a difficult task, but it does not involve doing any kind of sophisticated modifications to general "template" of a prompt.
Others, who I think do deserve to call themselves "Prompt Engineers" (and an awful lot more than that), have been writing about and utilizing the rich new eco-system
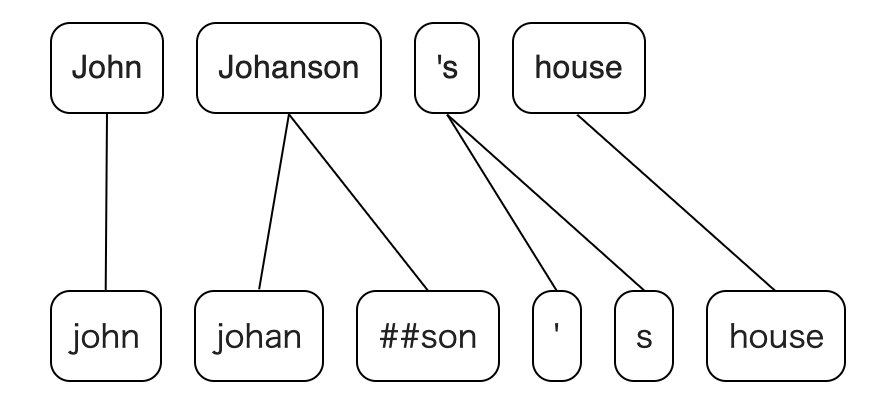
site: https://tamuhey.github.io/tokenizations/
Natural Language Processing (NLP) has made great progress in recent years because of neural networks, which allows us to solve various tasks with end-to-end architecture. However, many NLP systems still require language-specific pre- and post-processing, especially in tokenizations. In this article, I describe an algorithm that simplifies calculating correspondence between tokens (e.g. BERT vs. spaCy), one such process. And I introduce Python and Rust libraries that implement this algorithm. Here are the library and the demo site links:
| import torch | |
| import torch.nn as nn | |
| import torch.nn.functional as F | |
| # helpers | |
| def make_unit_length(x, epsilon=1e-6): | |
| norm = x.norm(p=2, dim=-1, keepdim=True) | |
| return x.div(norm + epsilon) |
| worker_processes 1; | |
| events { | |
| worker_connections 1024; | |
| } | |
| http { | |
| map $http_upgrade $connection_upgrade { | |
| default upgrade; | |
| '' close; |
See the official Differentiable Programming Manifesto instead.
https://eng.uber.com/michelangelo/
Finding good features is often the hardest part of machine learning and we have found that building and managing data pipelines is typically one of the most costly pieces of a complete machine learning solution.
A platform should provide standard tools for building data pipelines to generate feature and label data sets for training (and re-training) and feature-only data sets for predicting. These tools should have deep integration with the company’s data lake or warehouses and with the company’s online data serving systems. The pipelines need to be scalable and performant, incorporate integrated monitoring for data flow and data quality, and support both online and offline training and predicting. Ideally, they should also generate the features in a way that is shareable across teams to reduce duplicate work and increase data quality. They should also provide strong guard rails and controls to encourage and empower users to adop
| # Based on the example from the TensorFlow repository: https://github.com/tensorflow/tensorflow/ | |
| # https://github.com/tensorflow/tensorflow/blob/671baf080238025da9698ea980cd9504005f727c/tensorflow/examples/learn/text_classification_character_rnn.py | |
| from __future__ import absolute_import | |
| from __future__ import division | |
| from __future__ import print_function | |
| import argparse | |
| import sys |