Some stats: - Total number of links: 23983
ignoramous
taskylizard
/ fmhy.md
Last active
May 21, 2024 11:09
/r/freemediaheckyeah, in one single file (view raw)
joaocruz04
/ android_room_fts4.md
Last active
May 21, 2024 04:40
Enabling FTS4 on an Android + Room project
You can do a SQL text query by using the LIKE operator. The issue is that using it requires a lot of computation, as a complete string query is done. Also if you want to have more search options (more fields), your query will grow a lot in complexity. To solve this issue, there's a concept of virtual tables for full text search (FTS).
We will build our solution using Room (already set in the project). We're using version 2.2.0-rc01 for that.
With Room, the only thing we need is to create the new class with @FTS4 notation. By specifying contentEntity to be the Route class, it means that it will reuse the values from the Route table instead of populating this one with copies. The fields in question should match the ones from the Route table. In this example we only need the title.

yoavg
/ rl-for-llms.md
Last active
May 20, 2024 06:09
Yoav Goldberg, April 2023.
With the release of the ChatGPT model and followup large language models (LLMs), there was a lot of discussion of the importance of "RLHF training", that is, "reinforcement learning from human feedback". I was puzzled for a while as to why RL (Reinforcement Learning) is better than learning from demonstrations (a.k.a supervised learning) for training language models. Shouldn't learning from demonstrations (or, in language model terminology "instruction fine tuning", learning to immitate human written answers) be sufficient? I came up with a theoretical argument that was somewhat convincing. But I came to realize there is an additional argumment which not only supports the case of RL training, but also requires it, in particular for models like ChatGPT. This additional argument is spelled out in (the first half of) a talk by John Schulman from OpenAI. This post pretty much
thesamesam
/ xz-backdoor.md
Last active
May 19, 2024 20:15
xz-utils backdoor situation (CVE-2024-3094)
This is a living document. Everything in this document is made in good faith of being accurate, but like I just said; we don't yet know everything about what's going on.
On March 29th, 2024, a backdoor was discovered in xz-utils, a suite of software that
gtallen1187
/ slope_vs_starting.md
Created
November 2, 2015 00:02
A little bit of slope makes up for a lot of y-intercept
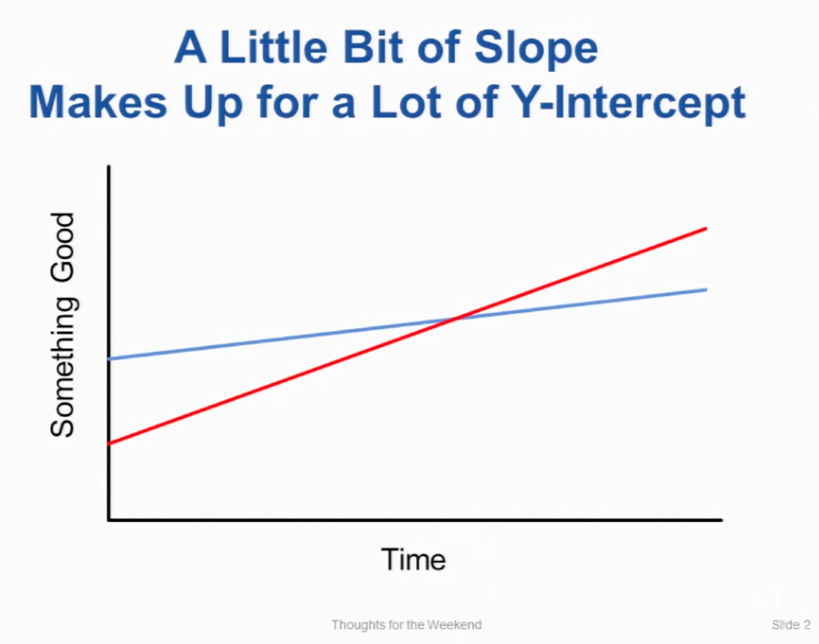
debasishg
/ gist:8172796
Last active
May 10, 2024 13:37
A collection of links for streaming algorithms and data structures
- Probabilistic Data Structures for Web Analytics and Data Mining : A great overview of the space of probabilistic data structures and how they are used in approximation algorithm implementation.
- Models and Issues in Data Stream Systems
- Philippe Flajolet’s contribution to streaming algorithms : A presentation by Jérémie Lumbroso that visits some of the hostorical perspectives and how it all began with Flajolet
- Approximate Frequency Counts over Data Streams by Gurmeet Singh Manku & Rajeev Motwani : One of the early papers on the subject.
- [Methods for Finding Frequent Items in Data Streams](http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.187.9800&rep=rep1&t
objcode
/ ConcurrencyHelpers.kt
Last active
May 2, 2024 08:05
Helpers to control concurrency for one shot requests using Kotlin coroutines.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| /* Copyright 2019 The Android Open Source Project | |
| * | |
| * Licensed under the Apache License, Version 2.0 (the "License"); | |
| * you may not use this file except in compliance with the License. | |
| * You may obtain a copy of the License at | |
| * | |
| * https://www.apache.org/licenses/LICENSE-2.0 | |
| * | |
| * Unless required by applicable law or agreed to in writing, software | |
| * distributed under the License is distributed on an "AS IS" BASIS, |
Get Git log in JSON format
git log --pretty=format:'{%n "commit": "%H",%n "abbreviated_commit": "%h",%n "tree": "%T",%n "abbreviated_tree": "%t",%n "parent": "%P",%n "abbreviated_parent": "%p",%n "refs": "%D",%n "encoding": "%e",%n "subject": "%s",%n "sanitized_subject_line": "%f",%n "body": "%b",%n "commit_notes": "%N",%n "verification_flag": "%G?",%n "signer": "%GS",%n "signer_key": "%GK",%n "author": {%n "name": "%aN",%n "email": "%aE",%n "date": "%aD"%n },%n "commiter": {%n "name": "%cN",%n "email": "%cE",%n "date": "%cD"%n }%n},'The only information that aren't fetched are:
%B: raw body (unwrapped subject and body)%GG: raw verification message from GPG for a signed commit
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| /** | |
| * Creates a new Uint8Array based on two different ArrayBuffers | |
| * | |
| * @private | |
| * @param {ArrayBuffers} buffer1 The first buffer. | |
| * @param {ArrayBuffers} buffer2 The second buffer. | |
| * @return {ArrayBuffers} The new ArrayBuffer created out of the two. | |
| */ | |
| var _appendBuffer = function(buffer1, buffer2) { | |
| var tmp = new Uint8Array(buffer1.byteLength + buffer2.byteLength); |
NewerOlder