Goals: Add links that are reasonable and good explanations of how stuff works. No hype and no vendor content if possible. Practical first-hand accounts of models in prod eagerly sought.

| # You will need to install https://github.com/cpursley/html2markdown | |
| defmodule Webpage do | |
| @moduledoc false | |
| defstruct [:url, :title, :description, :summary, :page_age] | |
| end | |
| defmodule WebSearch do | |
| @moduledoc """ | |
| Web search summarization chain |
The tables below show notable Twitter suspension reversals for each day since Elon Musk took over as owner and CEO.
All dates indicate when the suspension or reversal was detected, and the actual suspension or reversal may have been earlier. For most English-language accounts with large followings, this lag will generally not be longer than a few hours, but for accounts that have a small number of followers or that are outside the networks we are tracking, the difference can be larger, and in some cases an account on the list may have had its suspension reversed before 27 October 2022. These dates will get more precise as we refine the report.
Because of these limitations, this report should be considered a starting point for investigation, not a definitive list of suspension reversals.
| import pyphen | |
| import prodigy | |
| from prodigy.components.loaders import JSONL | |
| from prodigy.components.db import connect | |
| hyphenator = pyphen.Pyphen(lang="en_US") | |
| def construct_html(text): | |
| hyphend = hyphenator.inserted(text) |
| {"text":"Spam spam lovely spam!"} | |
| {"text":"I like scrambled eggs."} | |
| {"text":"I prefer spam!"} |
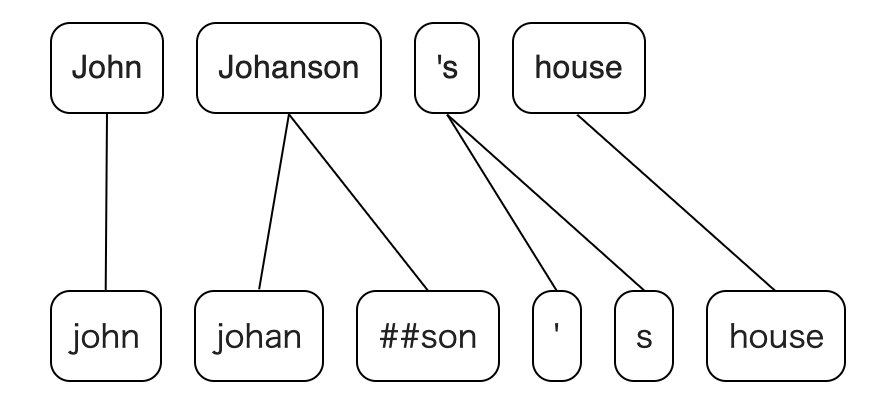
site: https://tamuhey.github.io/tokenizations/
Natural Language Processing (NLP) has made great progress in recent years because of neural networks, which allows us to solve various tasks with end-to-end architecture. However, many NLP systems still require language-specific pre- and post-processing, especially in tokenizations. In this article, I describe an algorithm that simplifies calculating correspondence between tokens (e.g. BERT vs. spaCy), one such process. And I introduce Python and Rust libraries that implement this algorithm. Here are the library and the demo site links:
| """ | |
| Example of a Streamlit app for an interactive Prodigy dataset viewer that also lets you | |
| run simple training experiments for NER and text classification. | |
| Requires the Prodigy annotation tool to be installed: https://prodi.gy | |
| See here for details on Streamlit: https://streamlit.io. | |
| """ | |
| import streamlit as st | |
| from prodigy.components.db import connect | |
| from prodigy.models.ner import EntityRecognizer, merge_spans, guess_batch_size |
| pip install streamlit | |
| pip install spacy | |
| python -m spacy download en_core_web_sm | |
| python -m spacy download en_core_web_md | |
| python -m spacy download de_core_news_sm |
| """See https://twitter.com/honnibal/status/1120020992636661767 """ | |
| import time | |
| import srsly | |
| from prodigy import recipe | |
| from prodigy.components.db import connect | |
| from prodigy.util import INPUT_HASH_ATTR, set_hashes | |
| from prodigy.components.filters import filter_duplicates | |
| def get_rank_priority(data): |