This is a very simple git workflow. It (and variants) is in use by many people. I settled on it after using it very effectively at Athena. GitHub does something similar; Zach Holman mentioned it in this talk.
Update: Woah, thanks for all the attention. Didn't expect this simple rant to get popular.
Special Thanks to friends for feedback:
mastermust always be deployable.- all changes made through feature branches (pull-request + merge)
- rebase to avoid/resolve conflicts; merge in to
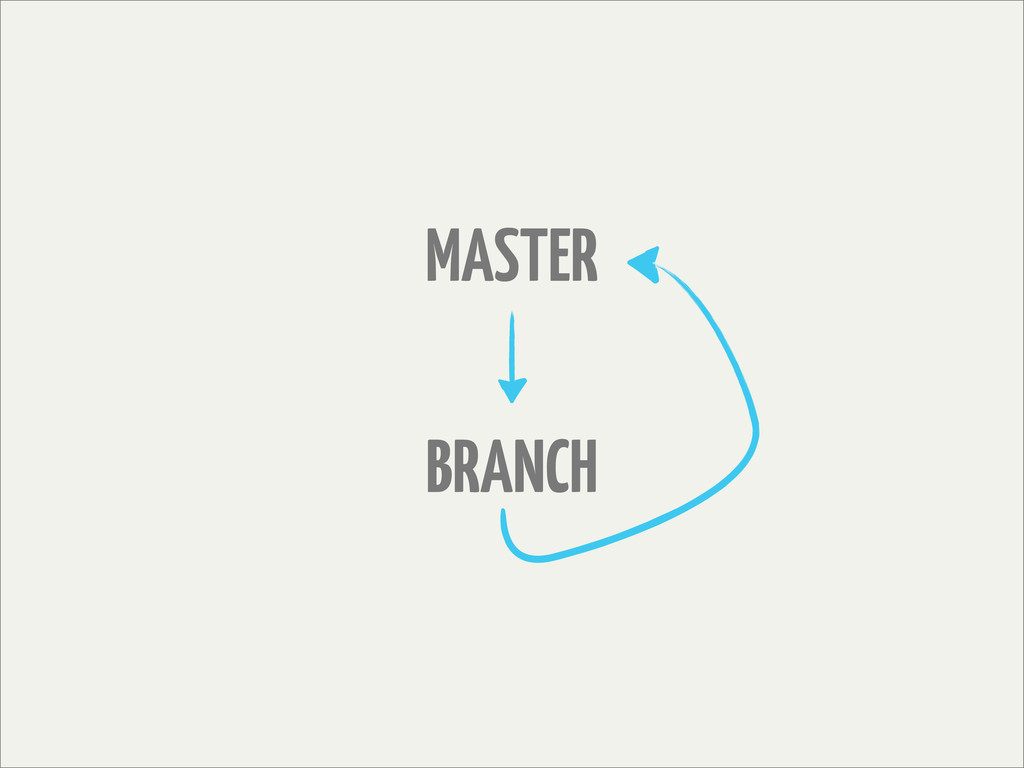
master
Or, as Zach Holman succinctly put it:

# everything is happy and up-to-date in master
git checkout master
git pull origin master
# let's branch to make changes
git checkout -b my-new-feature
# go ahead, make changes now.
$EDITOR file
# commit your (incremental, atomic) changes
git add -p
git commit -m "my changes"
# keep abreast of other changes, to your feature branch or master.
# rebasing keeps our code working, merging easy, and history clean.
git fetch origin
git rebase origin/my-new-feature
git rebase origin/master
# optional: push your branch for discussion (pull-request)
# you might do this many times as you develop.
git push origin my-new-feature
# optional: feel free to rebase within your feature branch at will.
# ok to rebase after pushing if your team can handle it!
git rebase -i origin/master
# merge when done developing.
# --no-ff preserves feature history and easy full-feature reverts
# merge commits should not include changes; rebasing reconciles issues
# github takes care of this in a Pull-Request merge
git checkout master
git pull origin master
git merge --no-ff my-new-feature
# optional: tag important things, such as releases
git tag 1.0.0-RC1# autosetup rebase so that pulls rebase by default
git config --global branch.autosetuprebase always
# if you already have branches (made before `autosetuprebase always`)
git config branch.<branchname>.rebase trueNo DO or DON'T is sacred. You'll obviously run into exceptions, and develop your own way of doing things. However, these are guidelines I've found useful.
- DO keep
masterin working order. - DO rebase your feature branches.
- DO pull in (rebase on top of) changes
- DO tag releases
- DO push feature branches for discussion
- DO learn to rebase
- DON'T merge in broken code.
- DON'T commit onto
masterdirectly.- DON'T hotfix onto master! use a feature branch.
- DON'T rebase
master. - DON'T merge with conflicts. handle conflicts upon rebasing.
Yes. Merge bubbles aren't inherently bad. They allow you to revert entire features at a time. They get confusing and annoying to deal with if they cross (commits interleave), so don't do that.

http://en.wikipedia.org/wiki/Atomic_commit#Atomic_Commit_Convention
Thanks wikipedia, I couldn't have put it better myself.
Why not gitflow or another complex workflow?
Be my guest. I've used gitflow and other similar models. After working in various teams, this is just what I've come to use. But next time you have to ask someone whether it is okay to push or pull from this or that branch, remember my face.
But, is it web-scale?
Friends claim more complex models are necessary for scaling large teams,
maintaining old releases, controlling information flow, etc. It very well may
be that using multiple mainlines (e.g. develop, stable, release, v2,
tested, etc) is exactly what fits your organization's constraints. That's
for you to decide, not me (unless we work together -- oh hi there!).
But you always have to wonder, "shouldn't I use tags for that"? For example, tracking releases on a branch is a bit silly. A release commit can be tagged. You can checkout a tag, just like any branch, or any commit, and do whatever it is you need to do.
My guess is this relationship holds:

So, perhaps taking five minutes to teach your team how to use checkout and
tag might save you more than 15% on car insurance.
Sometimes I see people forking repositories in order to issue pull-requests. Yes, you may have to do this when contributing to open-source projects you don't regularly contribute to. But, if you are a contributor, or working in the same org, get push rights on the repo and push all your feature branches to it. Issue pull requests from one branch to another within the same repo.
Up to you. Github does git merge --no-ff so that the commit message indicates
the pull request number. This is useful information to have, don't just throw
away history for the sake of it. You never know what will be useful to look at
in the future.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
Woah, thanks for the attention! Didn't expect this rant to get popular.
Credit where credit is due. Special thanks to friends who gave me feedback on this:
Responses below:
@zimbatm
That's probably safest. But I find when working with few others who are OK with rebasing, it can help keep things clean.
@hugoduncan
Awesome!
@nhance
Thanks! Cool tool! And good diagram :)
Want to note an important difference. Your
gitreflowencourages squash-merging. I don't, as I seek to preserve the individual commits. I do this because well-scoped atomic commits provide a phenomenal way to understand how a codebase works/evolved. (I imagine you [can] solve that problem by linking to the Pull-Request from your squash commit message?)@fhawkinsozer thanks! some very useful aliases there. Be careful though, overusing aliases can hide away what git is really doing underneath, and potentially confuse your team members. I like magic and shortcuts as much as the next guy, but i've learned magic tends to force more communication.
@pyriku
Not particularly, just:
@tjmcewan
Yeah! precisely. :) If you'd like me to add some of this to this gist, send me a diff.
@jsanders
Sure: forks add significant management complexity. For example, the fork owner has to make sure all changes from the mainline are pulled to his master. This can easily get out of sync as the developer's interest in the project waxes and wanes. It's best if there is just one mainline to worry about. Also, other users may seek fixes/experimental branches that haven't been merged yet. It's much easier to find those as branches in the same repo (particularly if they haven't been PRed yet) than explore the fork network, particularly when -- as a newcommer to a project -- it's very unclear what forks/devs are important to watch.
In my view, teams can reduce communication complexity by just sticking to one repo, and putting all branches there. (Also, if the repo is private, you're going to be doing this anyway :])
@rileytg see above. Happy to expand if you want more reasons?
I will say, if you don't trust your junior devs not to push onto another's branch (destroying code), or not to merge things into master (doing all sorts of bad things), you might want to re-teach your junior devs (or exchange them for new ones). Trust your team. Make it clear what is right and isn't right to do, but trust them.
@morhekil
Check out the comments to @pyriku above. You might find it easier to do this with tags. If it's easier with a branch for you, keep it up!
@nicotaing thanks! I think it's ok to rebase collaborative branch, iff the other devs are comfortable. It can work really well to fix stupid mistakes.
@gubatron learn
rebase. it will change your life.@lamont-granquist exactly! I applaud your workflow, good sir :)
@breck7 thanks!
@treseder
In the end, both branches will be merged into master sequentially, so you'll have to handle conflics there. If they touch the same files, or build upon each other, you might want to rebase the later feature branch on top of the earlier. When you merge the earlier into master, rebase the later over new master to keep things up to date. (Should I make a drawing of what i mean by this?)
It's worth noting that I'm wary of why the problem is coming up in the first place. While it's not uncommon to have two feature branches that depend on each other, wanting to test them together, not sequentially, can mean trouble. What if problems are emerging (or hiding) due to the interaction of the two feature sets? It's harder to reason about two sets of changin-and-potentially-broken code interacting together than it is to reason about only one. Of course, I don't know your constraints, no rule works always, and exceptions will emerge. But always worth stepping back and wondering whether there is a simpler way.
@twhaples
I imagine by tag-based builds, you mean builds on a specific release tag. Worth mentioning you can use a rolling tag (i.e.
test). Picking between branches or tags depends on what your team is more comfortable with. Updating tags requires-f, as it is not the main use case for tags. FWIW, in your case, I'd probably use branches too.